どうも、Tです。
Fessのクロール設定とパフォーマンスチューニングに必要な知識をつけるため検証してみた備忘録です。
目次
環境
Fess 15.1
# dnf list installed | grep fess fess.noarch 15.1.0-1 @@commandline

やりたいこと
Fessをデフォルト設定で使っていたところ、クロール処理のパフォーマンスがかなり悪いので、設定によってどのような違いがあるのか?チューニングは可能なのか?を探ってみました。


Fessは、Javaで作られているためJavaエンジニアであれば、コードを読みながら解析することもできそうですが、あまり得意な分野ではないため実際に動かしながら確認しています。
Fessで全文検索できるようになるまでには、大きく下記のような処理が行われます。
- Fessのクローラーでクロール対象(ファイルやWebの情報)を収集する
- クロールしたものをインデックスとしてOpenSearchに保存する
- FessからOpenSearchに保存したインデックスを利用して検索が可能になる
クローラージョブでは、1~2の処理を行っているため、この辺りの時間短縮を狙って確認しました。
結果
記事が長いので先に結果を記載しておきます。
気になる方は記事の内容をご確認ください。
改善状況
小さいファイルに関してはチューニングにより改善できましたが、大きいファイルに関してはチューニングで改善できませんでした。
| クロール対象 | デフォルト設定 | チューニング後 | やったこと |
|---|---|---|---|
| 1KBのテキストファイル1000個 | 5分 | 30秒 |
|
| 1MBのテキストファイル1000個 | 16分 | 16分 |
チューニングの検討順番
| 優先順 | 検討 | 方針 | 注意点 |
|---|---|---|---|
| 1 | CPU使用率上限の緩和 | CPU利用率の上限を可能な限り緩和する。可能であれば制限なしが良いと感じる。 デフォルト50%のCPU使用率上限が設けられて、処理の待ち時間が発生する頻度を減らすことできる。クロール対象が多い場合は、大きな削減が見込まれる。 | 他のサービスも動いている場合やクロール中にFessで検索を行う場合はパフォーマンス影響が発生する可能性がある。 |
| 2 | 間隔の短縮 | クロール先が許容できる範囲で間隔を0ミリ秒に近づける。 | 対象ドキュメントが大きいサイズの場合は、効果が薄い? |
| 3 | スレッド数の増加 | CPUコア数を超えて大き目のスレッド数にする。 | 対象ドキュメントが大きいサイズの場合は、効果が薄い? スレッド数が多すぎると逆に遅くなる可能性があるため計測しながら調整が必要。 |
| 4 | 複数クローラージョブを同時実行 | 本記事では確認していないが、クローラー対象が複数ある場合は、ジョブを並行で処理することによってトータル時間短縮が見込まれる。 | 同時に動作するスレッド数も増加するため、多くなりすぎないようにする。 |
| 5 | CPUを増やす。 | クローラー処理はCPU(スレッド数)が多ければ多いほど、同時に処理できるため時間短縮が見込まれる。 | 対象ドキュメントが大きいサイズの場合は、効果が薄い? |
わからなかった問題
対象のドキュメントのサイズが大きい場合は、クローラーではなくIndexUpdateの処理がボトルネックになっているようですが、これの対応方法がわかりませんでした。
OpenSearchへインデックスを渡す頻度?サイズ?を増やすことができれば、改善できそうな気がするのですが…。
Fessサーバースペック
今回の確認に使用したFessサーバのスペックになります。
| 項目 | 値 | 備考 |
|---|---|---|
| OS | Oracle Linux Server release 9.6 | |
| ロケーション | Proxmox VE上の仮想マシン | |
| CPU | 4コア | 推奨値最低 |
| メモリ | 16GB | 推奨値最低 |
| ディスク | 100GB | 推奨値最低は500GB以上 仮想マシンのディスクは、Proxmox VEに装備しているSSDにディレクトリタイプのストレージを作成して割り当てています。 |


テストファイル作成
Fessは、ファイル共有やWebなどさまざまなものを収集可能ですが、今回は確認のしやすいさからOSのファイルシステム上のファイルをクロールして確認しています。
テストに利用したファイルは下記になります。
| 項目 | 小さいファイル | 大きいファイル |
|---|---|---|
| 作成場所 | /fess-test/small | /fess-test/large |
| ファイル種類 | テキスト | テキスト |
| サンプルファイル | small_1KB.txt | large_1MB.txt |
| 1ファイルサイズ | 1KB | 1MB |
| ファイル数 | 1000ファイル | 1000ファイル |
Fessの検索テスト用にデータが公開されていたので、テキストファイルをそれぞれ上記のサイズになるようにテキストコピペしました。

小さいファイル作成
小さいテスト用ファイルを作成します。適用なディレクトリを作成し、テスト用ファイルを配置します。
# cd /fess-test/small/ # ls -lha total 4.0K drwxr-xr-x 2 root root 27 Aug 8 11:22 . drwxr-xr-x 4 root root 32 Aug 8 10:44 .. -rw-r--r-- 1 root root 1.1K Aug 8 10:50 small_1KB.txt
1000ファイルになるようにコピーします。
# for i in {1..999};do cp small_1KB.txt small_1KB_${i}.txt;done
1万ファイル作成できました。
# ls -1 | wc -l 1000
容量は4MBほどです。現代はだいたいブロックが4KBで書き込まれていると思うので、想定通りです。
# du -sh . 4.0M .
大きいファイル作成
大きいテスト用ファイルを作成します。適用なディレクトリを作成し、テスト用ファイルを配置します。
# cd /fess-test/large/ # ls -lha total 1.1M drwxr-xr-x 2 root root 27 Aug 8 10:44 . drwxr-xr-x 4 root root 32 Aug 8 10:44 .. -rw-r--r-- 1 root root 1.1M Aug 8 10:44 large_1MB.txt
1000ファイルになるようにコピーします。
# for i in {1..999};do cp large_1MB.txt large_1MB_${i}.txt;done
1万ファイル作成できました。
# ls -1 | wc -l 1000
容量は1GBほどです。こちらも代替想定の容量になりました。
# du -sh . 1004M .
前提
共通設定値
Fessはインストール後のデフォルト設定で確認しています。
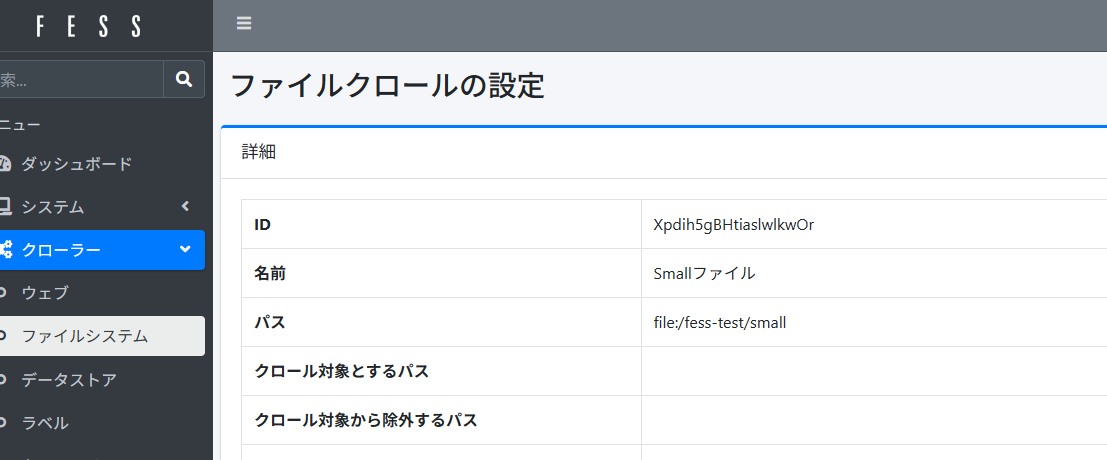
小さいファイルと大きいファイルの領域のクロールで比較していくため、下記2つのファイルシステムのクロール設定を利用します。
| クローラ名 | クロール対象とするパス |
|---|---|
| Smallファイル | file:/fess-test/small |
| Largeファイル | file:/fess-test/large |
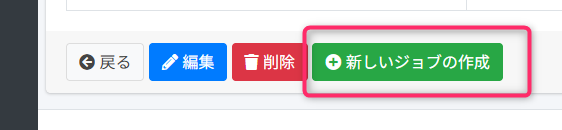
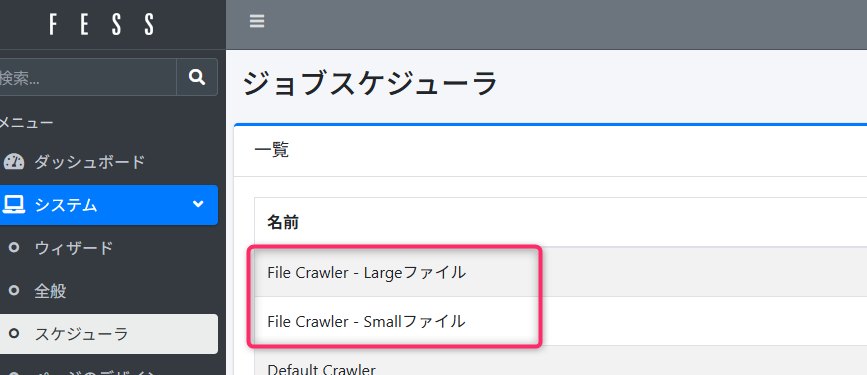
それぞれ別のジョブとして実行できるように、クロール設定下部の「新しいジョブの作成」からデフォルトでジョブを作成しています。
実施順番
確認は下記の順番で実施するようにしています。
- 小さいファイルでインデックス作成
- インデックス作成の時間を確認
- インデックスをすべて削除
- 大きいファイルインデックス作成
- インデックス作成の時間を確認
- インデックスをすべて削除
- 次の確認内容を実施(以下、1から実施)
インデックス作成にかかった時間は、「システム情報」->「ジョブログ」画面で確認できる開始時間・終了時間から確認しています。秒数はざっくりまとめました。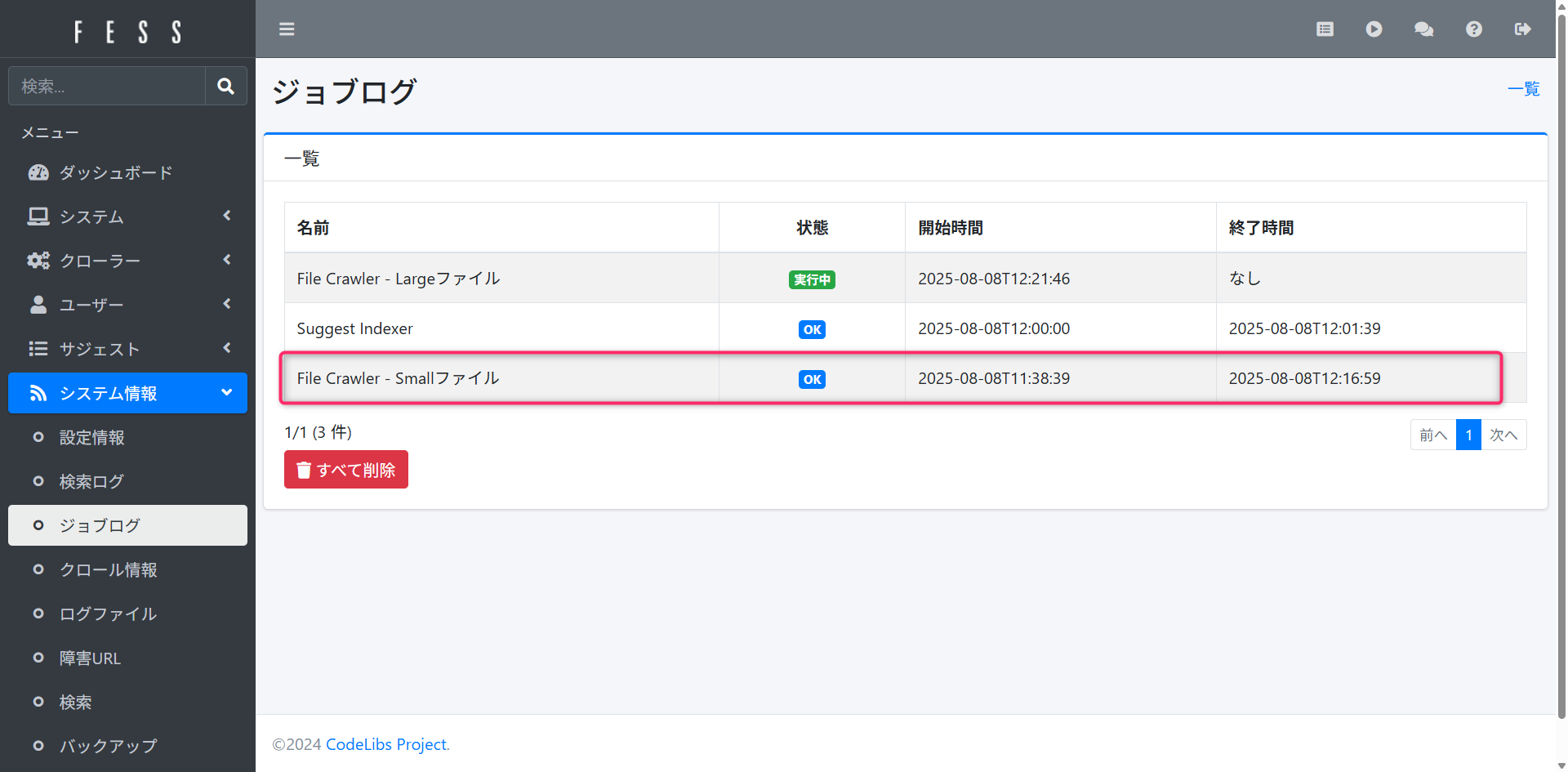
インデックスの削除方法については、下記の記事にまとめました。

クロール設定のチューニング
デフォルト値
| クローラ名 | スレッド数 | 間隔 | ジョブにかかった時間 |
|---|---|---|---|
| Smallファイル | 5 | 1000ミリ秒 | 5分 |
| Largeファイル | 5 | 1000ミリ秒 | 16分 |
Largeファイルの方は、テキストの量も多いため時間が長くなっています。
また、ファイルが大きい場合、IndexUpdaterというOpenSearchへ保存している(と思われる)処理が長く、OpenSearchのCPU使用率も高くなるような動きになっています。
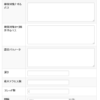
スレッド数変更
クローラの設定にあるスレッド数とは、クローラが実行するスレッド数です。つまり、スレッド数が5の場合、ジョブで実行すると5ファイルずつファイルの収集をしていきます。
今回、CPUは4コアしかありませんが、スレッド数を増やすことでCPUの空きなどをうまいこと使ってくれてジョブの時間が短くなるか確認しました。
Fessのドキュメントの不思議なところは新しいドキュメントになるたびに説明が割愛されて簡素になっています…。古いFess 8.0から確認しています。

| クローラ名 | スレッド数 | 間隔 | ジョブにかかった時間 |
|---|---|---|---|
| Smallファイル | 10 | 1000ミリ秒 | 3分 |
| 20 | 2分 | ||
| 30 | 1分30秒 | ||
| Largeファイル | 10 | 14分 | |
| 20 | 14分 | ||
| 30 | 14分 |
スレッド数を増やすことでジョブの時間を短くできることは確認できました。物理コア以上のスレッド数を指定しても、よい感じで処理してくれているようです。
しかし、スレッド数を増やしても倍々で早くなるわけであはりませんでした。特にLargeファイルについては、10スレッドでは多少時間短縮されましたが、20スレッド以上では誤差レベルでした。ある程度の改善の期待はあるものの劇的に改善するものではないこと、スレッド数を増やしすぎるとコンテキストスイッチのコストが増えて、逆に遅くなてしまう可能性もあるため、計測しながら調整する必要がありそうです。
間隔変更
間隔はドキュメントをクロールする間隔です。デフォルトの1000ミリ秒で、スレッドが5の場合、1秒間隔で5つのファイル(5スレッド分)のファイルを取得するようになります。
間隔を短くすることでジョブの時間が短くなるか確認しました。
Fessのドキュメントの不思議なところは新しいドキュメントになるたびに説明が割愛されて簡素になっています…。古いFess 8.0から確認しています。
| クローラ名 | スレッド数 | 間隔 | ジョブにかかった時間 |
|---|---|---|---|
| Smallファイル | 5 | 500ミリ秒 | 3分 |
| 100ミリ秒 | 1分 | ||
| 0ミリ秒 | 1分 | ||
| Largeファイル | 500ミリ秒 | 14分 | |
| 100ミリ秒 | 13分30秒 | ||
| 0ミリ秒 | 13分30秒 |
間隔を短くすることでジョブ時間を短くできることを確認できました。Smallファイルでは明かに改善されているため、チューニングする際は、まず検討したい項目になりそうです。クロール先の負荷や要件を満たす範囲で可能な限り短くするのが良いと思われます。
Largeファイルについては、多少の改善はありましたが500ミリ秒以下は誤差レベルです。間隔では、ファイルをクロールする時間を短くしていますが、ファイルが大きいとIndexUpdaterのOpenSearchへのインデックス登録に時間を要してしまうのがネックになっていると思われます。
スレッド数・間隔変更
スレッド数と間隔の両方を変更して、どの程度まで改善できるか確認しました。
| クローラ名 | スレッド数 | 間隔 | ジョブにかかった時間 |
|---|---|---|---|
| Smallファイル | 30 | 0ミリ秒 | 1分 |
| Largeファイル | 13分30秒 |
目立った改善は見られませんでした。Smallファイルについては間隔が短く早く処理が行われているため、CPUに空きがなくスレッドが良い感じに回れていないためと思われます。Largeファイルについては、やはりIndexUpdaterの処理がネックになっていると思われます。
Fess自身のチューニング
CPU使用率上限変更
Fessでは、デフォルト設定でCPU使用率が50%を超えると処理に待ち時間が発生します。このCPU使用率の上限を引き上げることで処理時間が短くなるか確認しました。
CPU使用率上限の変更方法は、下記の記事にまとめました。


| クローラ名 | スレッド数 | 間隔 | CPU使用率上限 | ジョブにかかった時間 |
|---|---|---|---|---|
| Smallファイル | 30 | 0ミリ秒 | 0 (無制限) | 30秒 |
| Largeファイル | 16分 |
CPU使用率を無制限にしても100%に張り付くなどは確認できませんでしたが、1000ファイルと少ないためかもしれません。
Smallファイルに関しては体感としても明らかに早くなっていると感じましたが、Largeファイルに関してはむしろ遅くなりました…なぜ?
CPUコアの増強
Fessのチューニングだけでは限界を感じたので、CPUコアを2倍の8コアに増やして速くなるか確認しました。
| クローラ名 | スレッド数 | 間隔 | CPU使用率上限 | ジョブにかかった時間 |
|---|---|---|---|---|
| Smallファイル | 30 | 0ミリ秒 | 0 (無制限) | 約20秒 |
| Largeファイル | 13分 |
Smallファイルは明らかに速くなりました。Largeファイルについては、スレッド数や間隔変更時とほぼかわりませんでした。
Appendix
リソース確認
Fessのパフォーマンスは、CPU・メモリおよびそれらのリソースを使うFessで動くJavaプロセスの状況を見ながら確認していく必要があります。サーバOSのリソース状況についてはdstatコマンドを使って確認しました。dstatは、CPUコア毎とメモリを同時に出力できなかったため別々に確認しています。
CPUリソースは、下記のようにCPUコアを指定することで、コア毎の利用状況を確認できます。
# dstat -t -C 0,1,2,3
メモリリソースは、下記のコマンドで確認しました。
# dstat -tv
ログ確認
管理画面からはどの程度インデックス化されているか、どのような処理が行われているかわかりません。
チューニングの際は、ログファイルを確認しながらジョブを実行するとわかりやすいです。
| ログ | 内容 |
|---|---|
| /var/log/fess/fess-crawler.log | Fessのクロールに関するログです。 リソース不足など何か問題があればこのログに出力されます |
| /var/log/fess/fess-urls.log | クロールされているドキュメントのログです。fess-crawler.logにもクロール状況は出力されていますが、こちらはドキュメントのみのログのため見やすいです。 https://www.chazine.com/archives/4355 |
| /var/log/opensearch/opensearch.log | OpenSearchのログです。FessからOpenSearchにインデックスしているあたりでリソース不足などあればこちらに出力されます。 |
Fess回りのログは、ログレベルを変更することもできるため、下記を参照すると良いです。




差分クロールが一般的な認識の差分とは違う問題
Fessには、「最終更新日時の確認」という設定項目があります。当初、最初のクロールに時間がかかっても差分が短くなるなら良いかと考えていました。
https://fess.codelibs.org/ja/15.1/admin/general-guide.html
最終更新日時の確認
差分クロールを行う場合に有効にします。
差分クロールだと、クロール処理から外れると考えていましたがクロール処理の対象になります。この辺り理解ができなかったのですが、下記の記事が非常に参考になりました。






参考













まとめ
実際の環境では、ドキュメントサイズは大小混合しているので、スレッド数・間隔を変更しながら調整するしかなさそうです。
最後はCPU数のマシンパワーでぶん殴るしかなさそうなのが残念というか…まだ見つけられていないパラメーターがあるかもしれないので探していきたいです…。