どうも、Tです。
vSphere HAのアドミッションコントロールのリソースの使い方が、いつもあやふやになるのでちゃんとまとめてみることにしました。
目次
環境
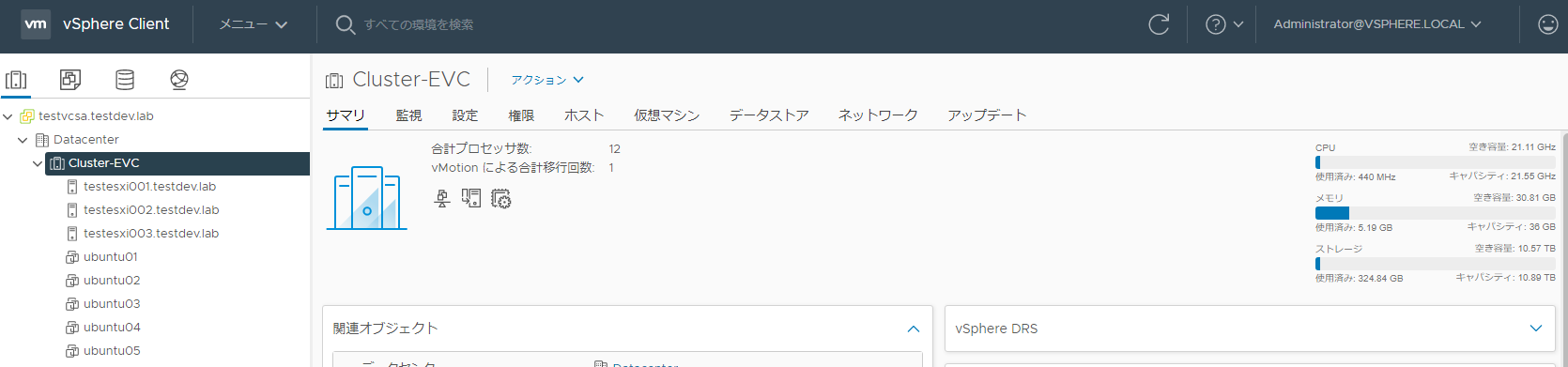
vSphere環境
- vCenter Server 7.0.2 18356314
- ESXi 7.0.2, 17867351
vCenterはリソース計算の邪魔にならないように、検証用のクラスタとは別クラスタに作成しています。
ESXiホストはNested ESXiとして仮想マシンとして構築しています。検証のクラスタ「Cluster-EVC」CPU・メモリリソースは、下記のようになっています。
| ホスト名 | CPU周波数 | CPUコア数(物理) | メモリ容量 |
| testesxi001 | 1.8GHz | 4 | 12GB |
| testesxi002 | 1.8GHz | 4 | 12GB |
| testesxi003 | 1.8GHz | 4 | 12GB |
| Cluster-EVCクラスタのリソース合計 | 1.8GHz×12コア=21.6GHz | 36GB | |
DRSは、完全自動化で設定しています。
テスト用仮想マシン
- Gest OS:Ubuntu 20.04.1 LTS
下記のvCPUとメモリを割り当てています。
| ホスト名 | CPUコア | メモリ | 備考 |
| ubuntu01 | 2vCPU | 8GB | |
| ubuntu02 | 2vCPU | 8GB | |
| ubuntu03 | 2vCPU | 8GB | |
| ubuntu04 | 2vCPU | 8GB | |
| ubuntu05 | 2vCPU | 8GB |
アドミッションコントロールとは
アドミッションコントロールの内容について一旦まとめてみます。下記のドキュメントから色々引用しています。


アドミッションコントロールの役割
アドミッションコントロールは、vSphere HA設定の1つになります。ホスト障害でHAが発生した際に、HAされた仮想マシンが起動できるように事前にリソースを確保する役割があります。アドミッション(入会?別ホストでの起動許可)をコントロールするという意味です。
アドミッションコントロールでリソースを確保した以上のリソースを使われようとした場合に、仮想マシンの下記のアクションを制限します。
- 仮想マシンのパワーオン
- 仮想マシンの移行
- 仮想マシンの CPU またはメモリ予約の増加
また、アドミッションコントロールの対象となるリソースは、CPUとメモリだけです。ネットワークやストレージのリソースに対する制御は行われません。
方式は3種類
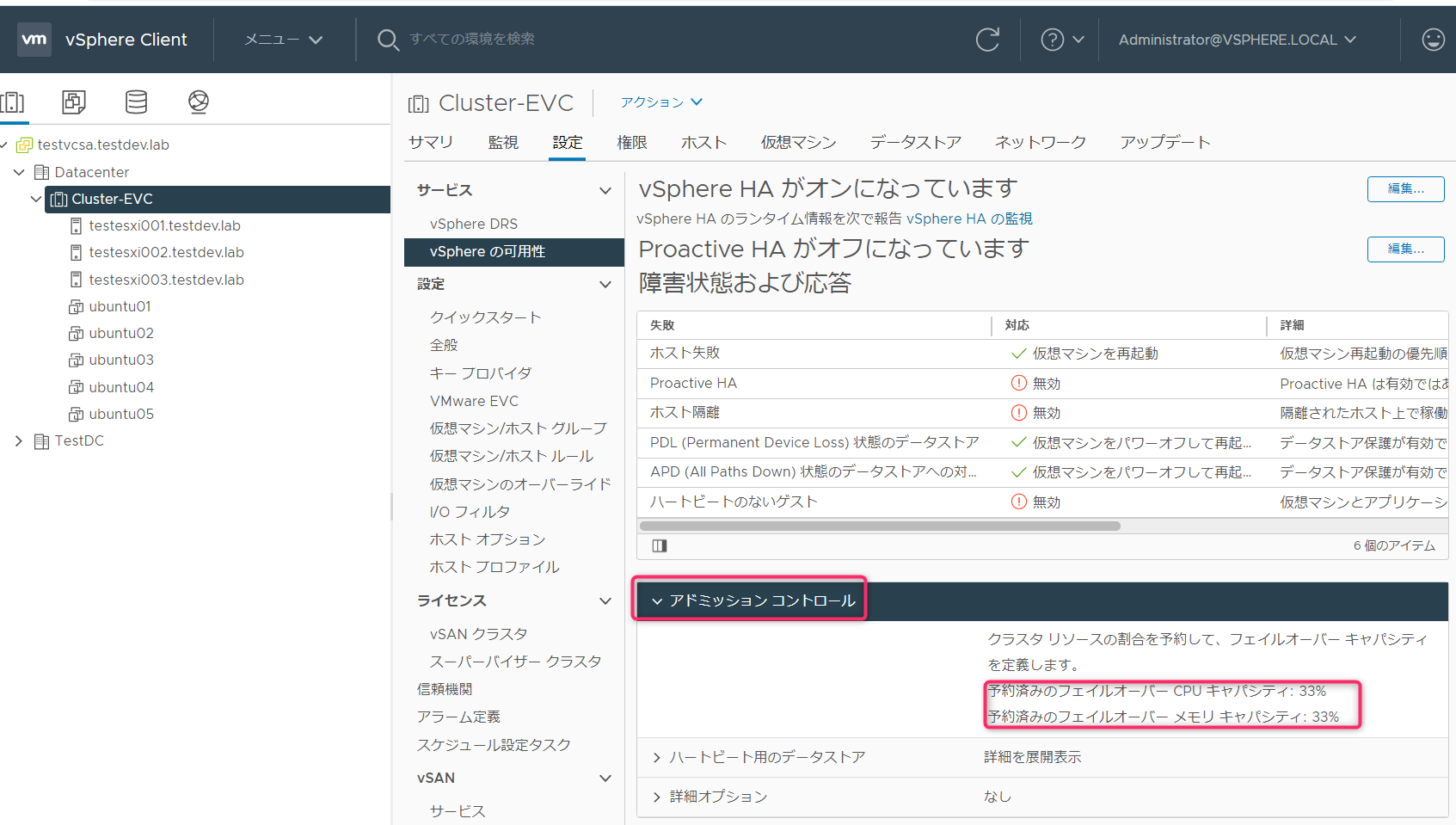
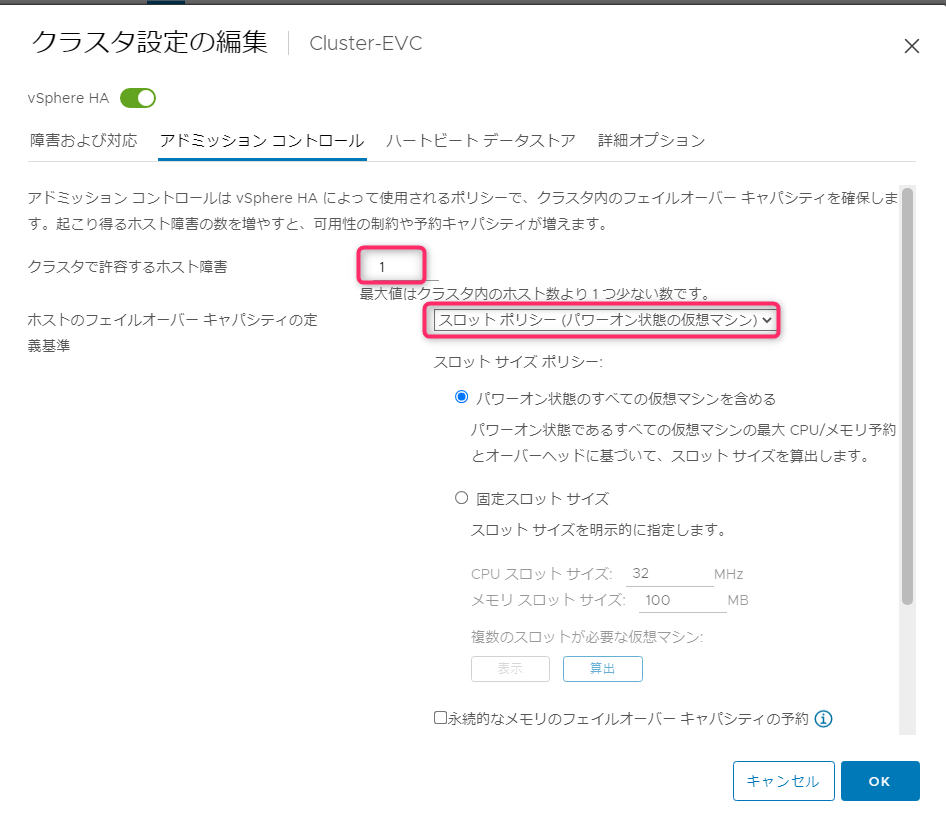
アドミッションコントロールの設定は、「クラスタ」->「設定」->「vSphereの可用性」->「編集」から行えます。
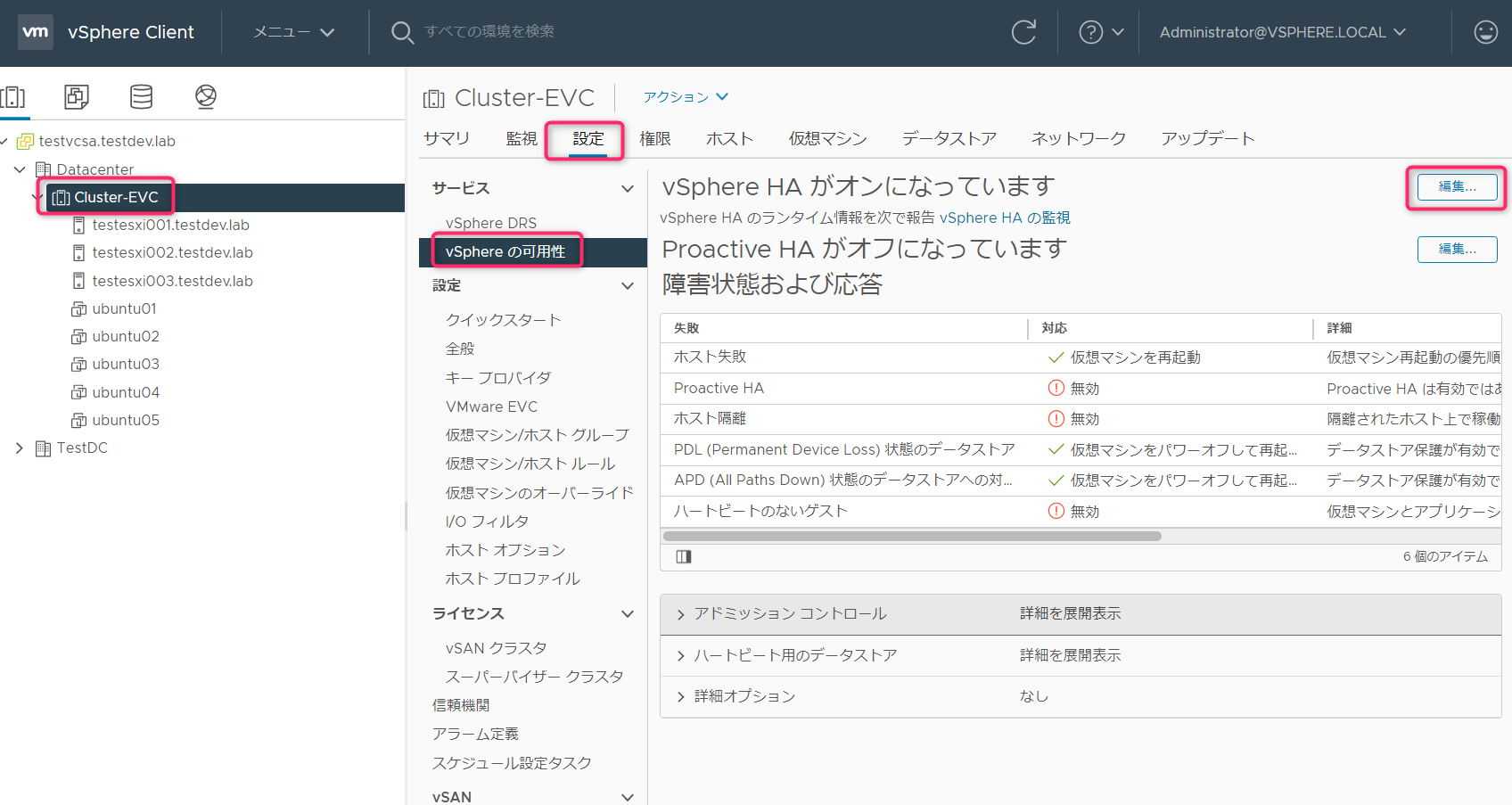
アドミッションコントロールタブの「ホストのフェイルオーバーキャパシティの定義基準」のリストで設定を選択します。
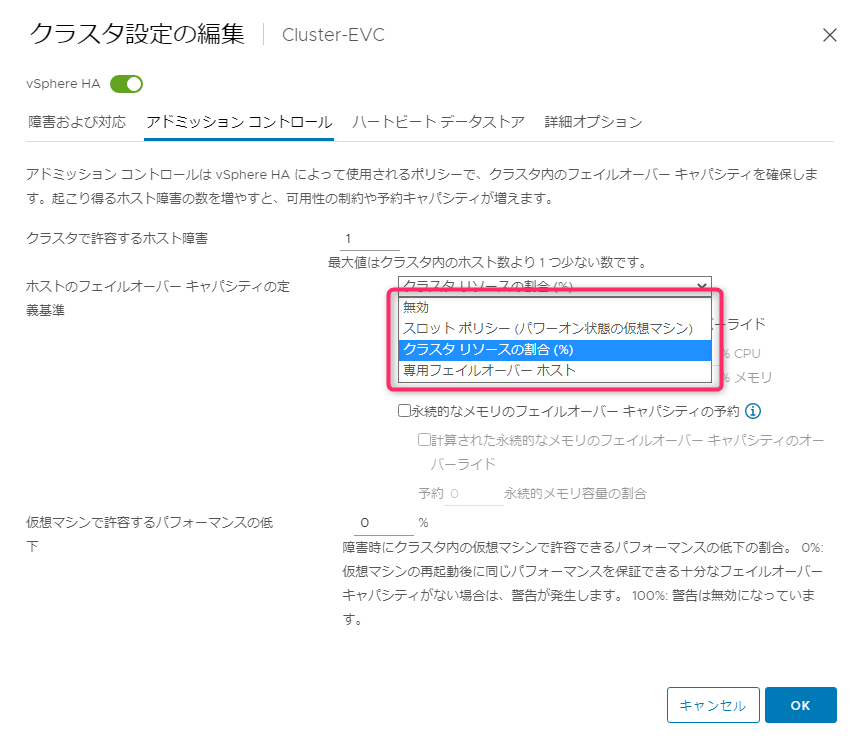
アドミッションコントロールでリソースを確保する方式として、下記の3種類があります。
- クラスタリソースの割合
- スロットポリシー
- 専用フェイルオーバーホスト
4つ目の設定の「無効」は、アドミッションコントロールを行わない意味なので今回は考えません。本記事では3種類の設定について、どのようにリソース確保されるかを確認します。
考慮される仮想マシンリソースは予約済みCPU・メモリ
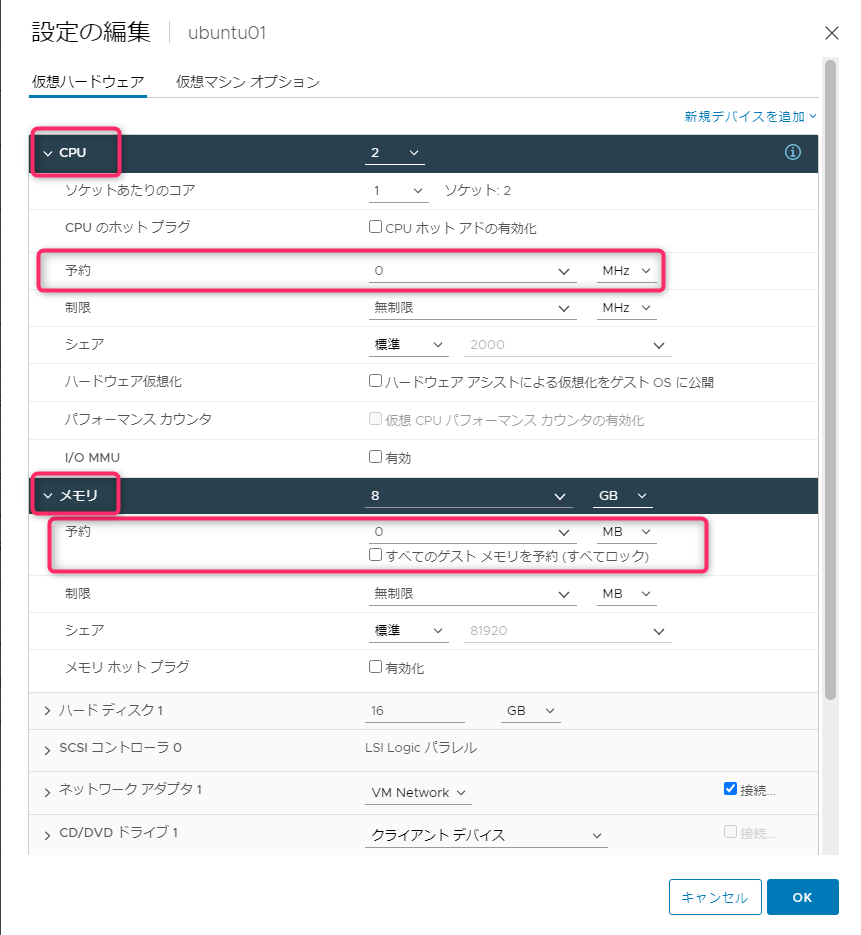
アドミッションコントロールでは、リソースを確保するために各仮想マシンのリソースを評価します。この評価の対象となるのは、仮想マシンに設定したCPU・メモリの予約値です。
仮想マシンに割り当てた、vCPU・メモリや実際に消費しているリソースは評価対象ではないことに注意が必要です。
役割によって評価方法が異なるので、後述で補足します。
考慮されるvSphereのリソースはルートリソースプールのCPU・メモリ
アドミッションコントロールで、リソース確保のためにvSphere HAが設定されているクラスタ全体のリソースも評価しなければなりません。
クラスタ全体のリソースの評価対象となるのは、物理リソースの合計ではなくルートリソースプールであることに注意が必要です。ルートリソースプールは、各ホストの物理リソースからESXiとして稼働するために必要となるリソースを減算し仮想マシンを稼働するための(仮想マシンの予約値として使用できる)リソースとなります。この計算は、vSphere内で自動的に計算されるため、ルートリソースプールの値を手動で変更することはできません。
クラスタのリソース状況として、サマリ画面でCPUとメモリのキャパシティが表示されますが、この表示はクラスタに参加してメンテナンスモードではないホストの物理リソースの合計値になります。こちらは、アドミッションコントロールの評価対象ではありません。
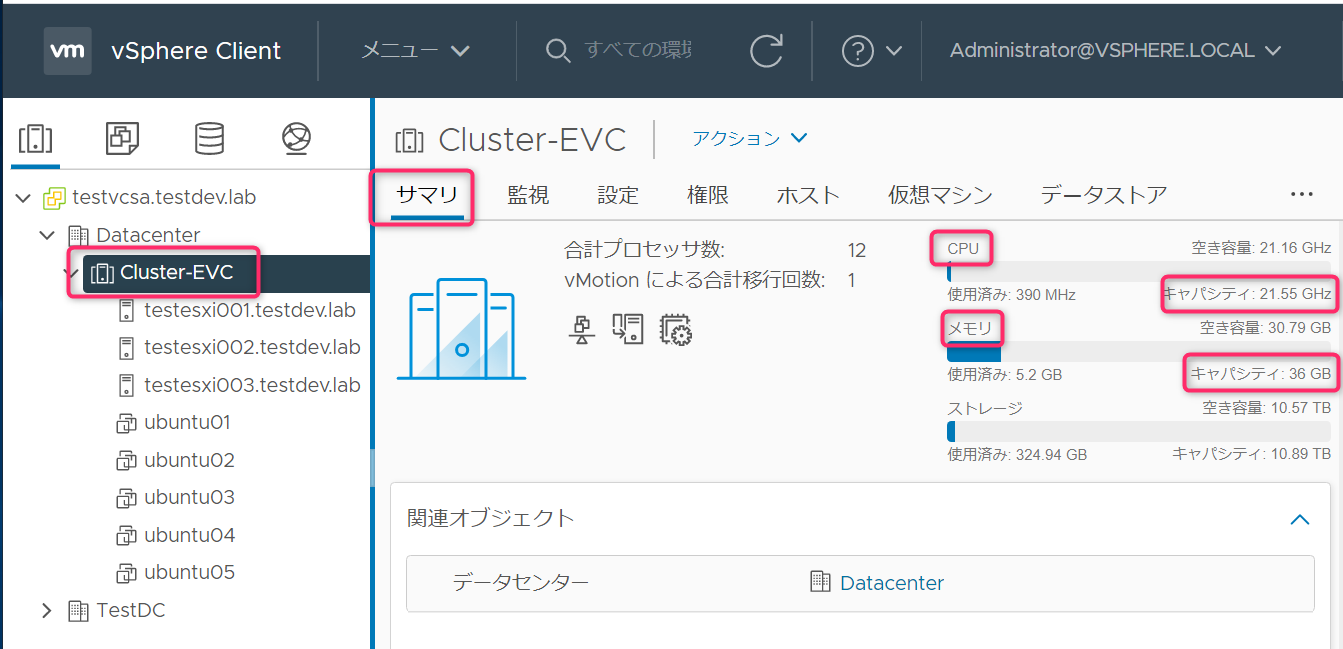
アドミッションコントロールのクラスタのCPUリソースの評価対象のルートリソースプールのCPUリソースは、「クラスタ」->「監視」->「リソース割り当て」->「CPU」->「予約キャパシティの合計」で確認ができます。
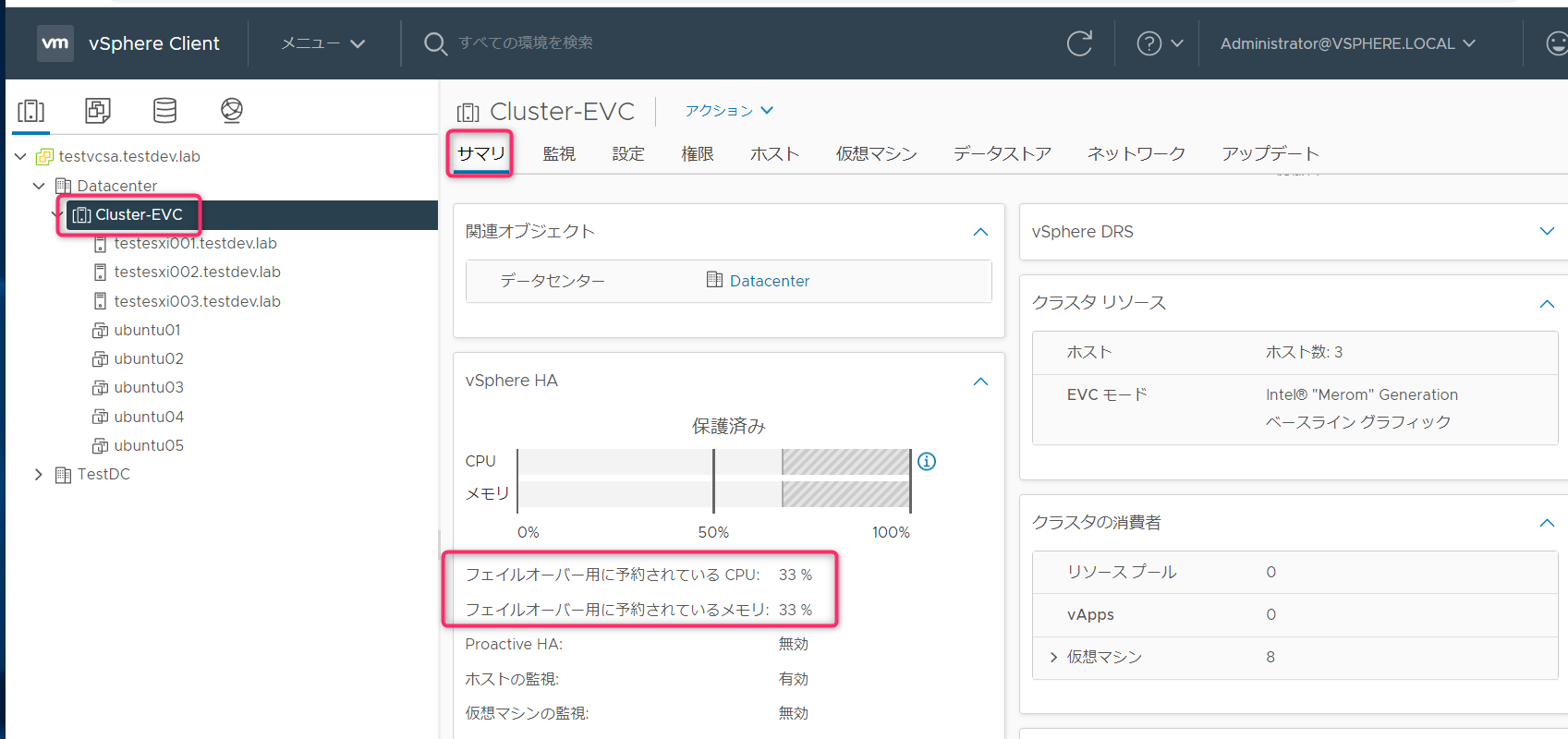
クラスタ合計キャパシティは、クラスタのサマリタブに表示されている物理リソースの合計です。
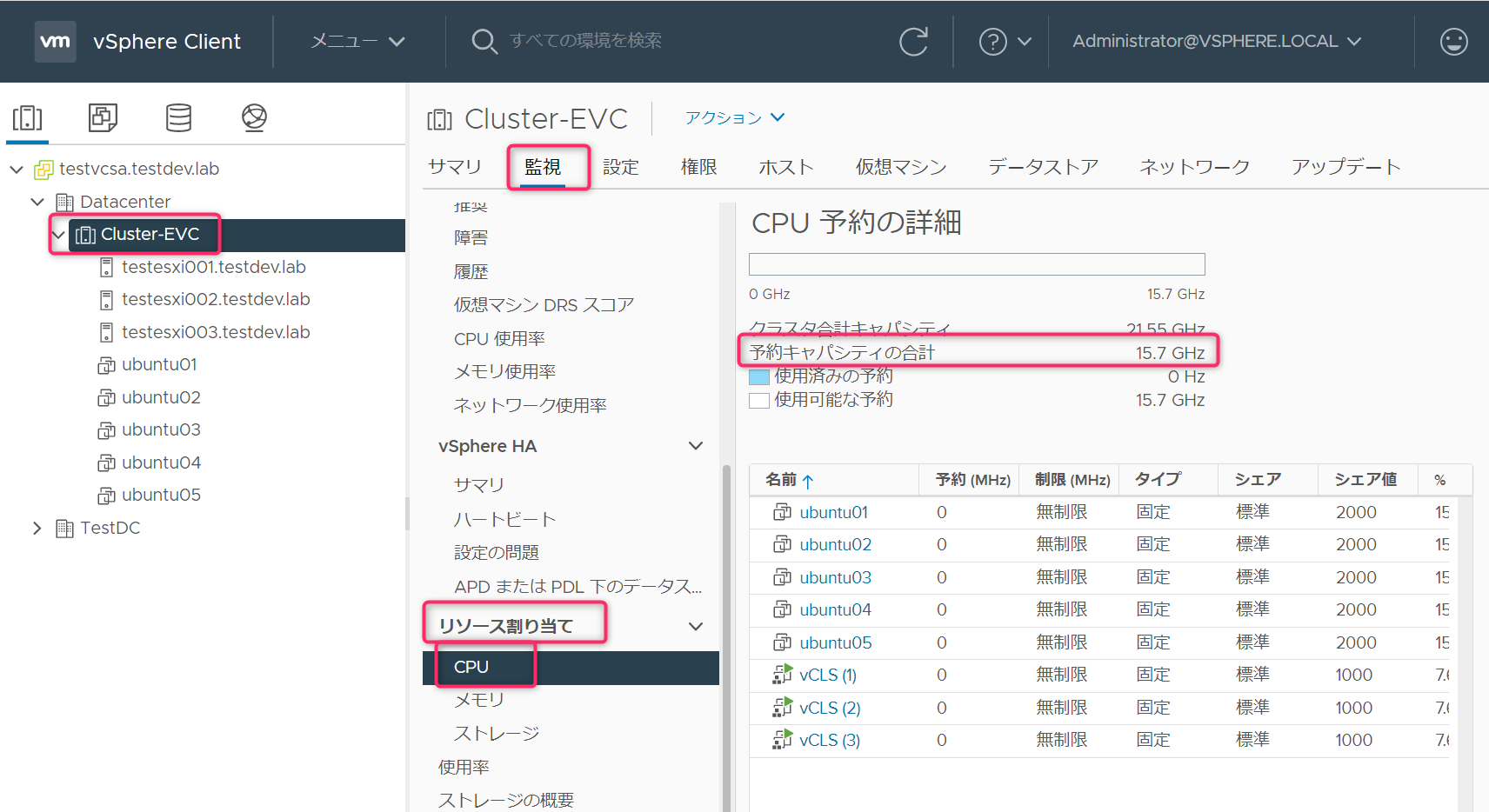
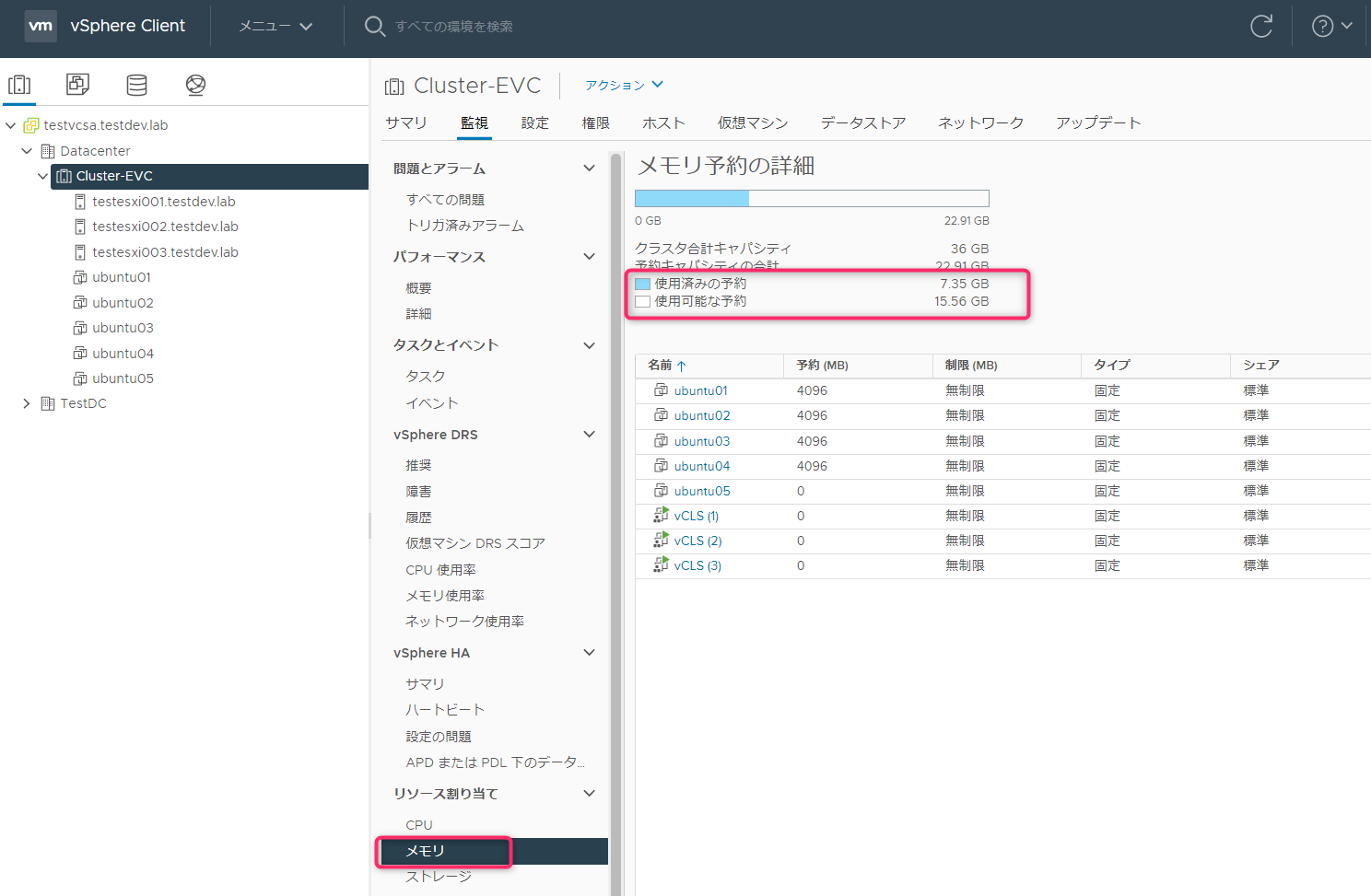
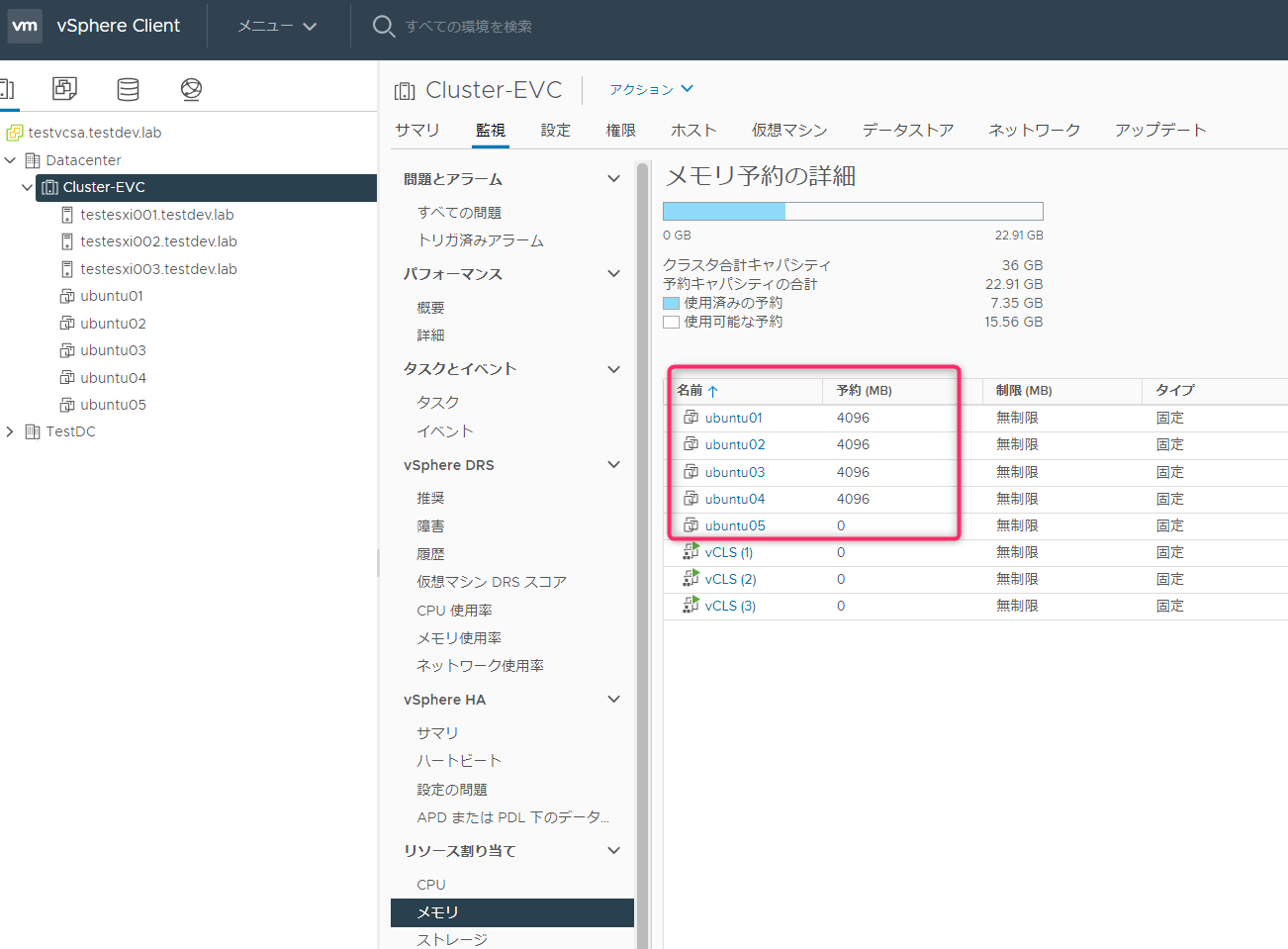
アドミッションコントロールのクラスタのメモリリソースの評価対象のルートリソースプールのメモリリソースは、「クラスタ」->「監視」->「リソース割り当て」->「メモリ」->「予約キャパシティの合計」で確認ができます。
クラスタ合計キャパシティは、クラスタのサマリタブに表示されている物理リソースの合計です。
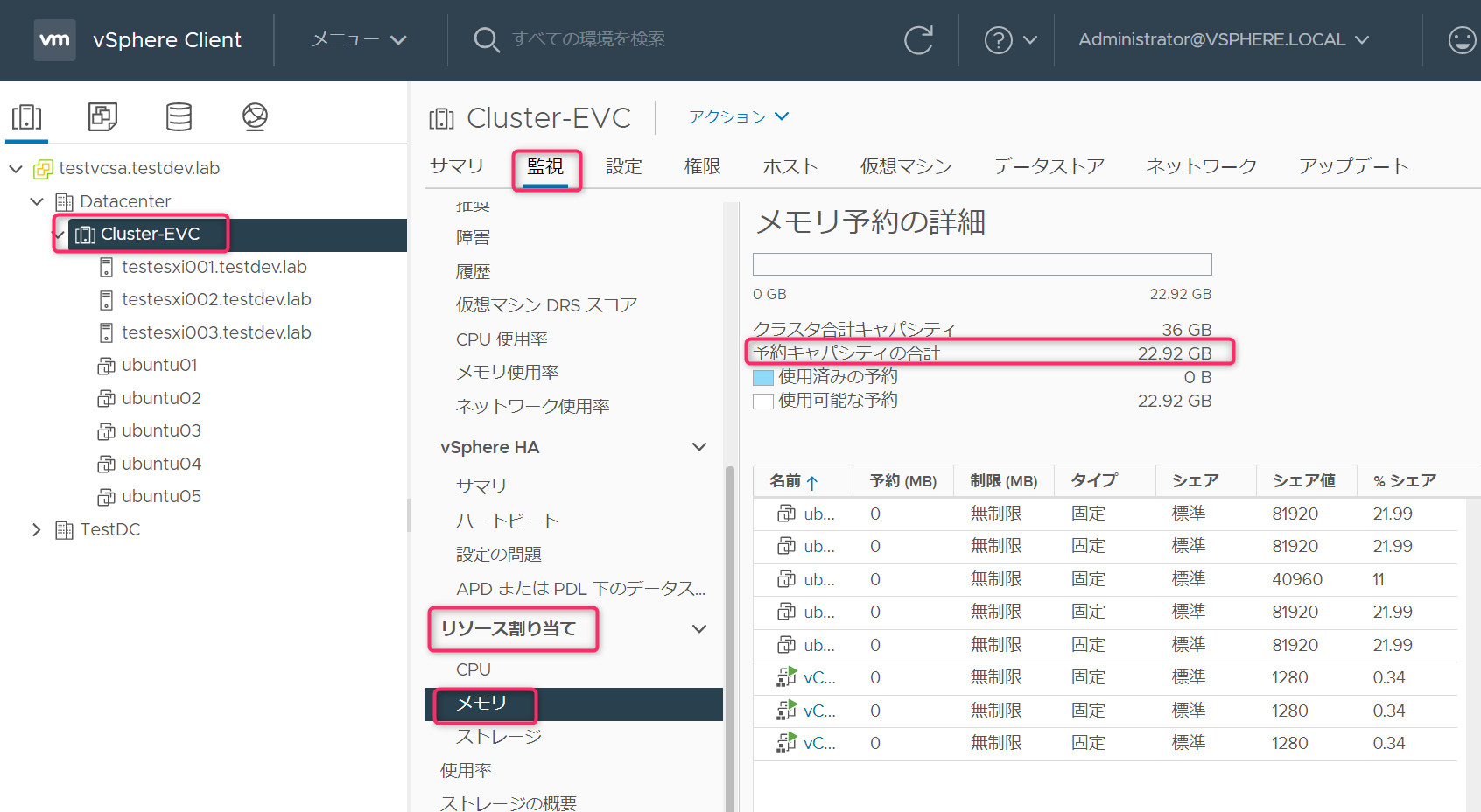
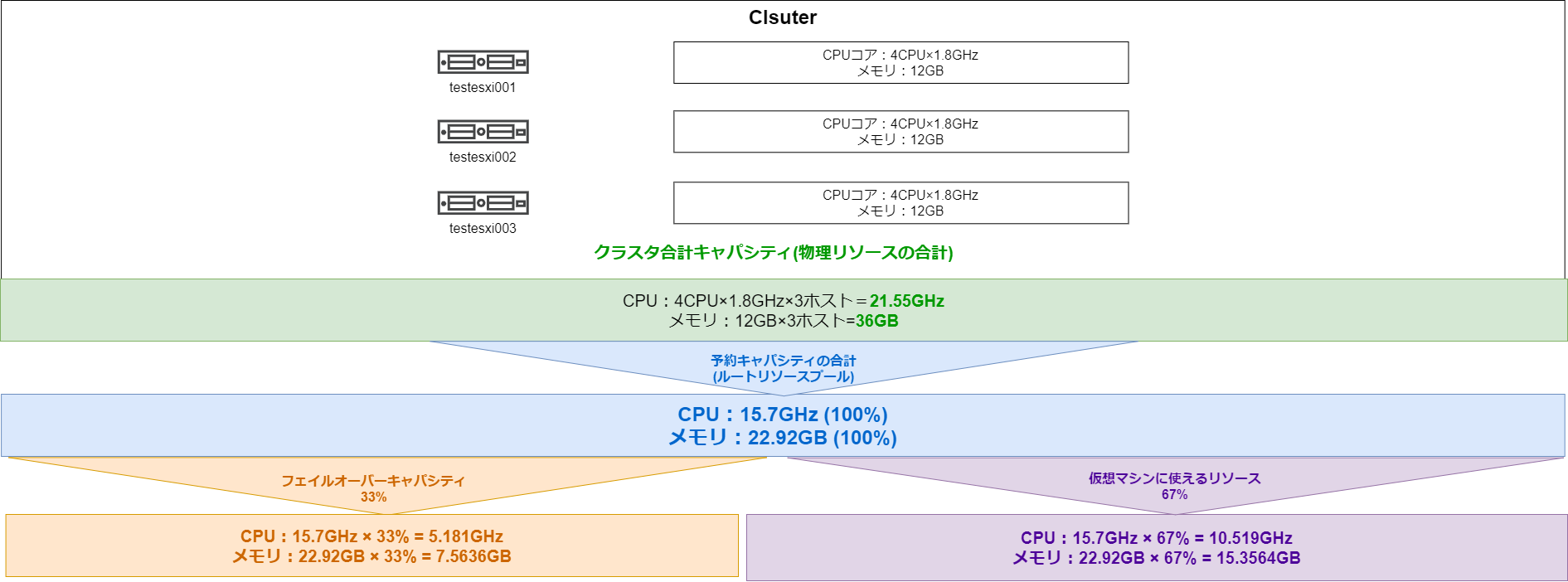
ここまでの情報をまとめると下記のようになります。CPUの合計は正確には21.6GHzになりますが、表示されている21.55GHzを正として扱います。

| 項目 | CPU | メモリ |
| クラスタ合計キャパシティ | 21.55GHz | 36GB |
| 予約キャパシティの合計 | 15.9GHz | 22.92GB |
| 差分 | 5.65GHz | 13.08GB |
アドミッションコントロールで、評価されるのは予約キャパシティの合計(仮想マシンの予約に割当できる値)です。差分の値は、ESXiホストが稼働するために必要と判断したシステムリソースです。
この差分は、vSphere内で自動計算されているため今回の検証環境では、ホスト1台あたり下記のシステムリソースが必要と判断されたようです。
- 5.65GHz / 3ホスト = 1.88GHz
- 13.08GB / 3ホスト = 4.36GB
このシステムリソースは、同じ環境でもESXiホストの再起動や稼働マシンの稼働状況で1GB前後(メモリ搭載容量では数GB以上)程度変化しました。また、搭載ハードウェアの容量、NSX、vSAN、サードパーティのVIB導入状況により変わってくるのでどの程度のルートリソースプールがあるのかは実機を確認するのが確実だと考えています。
今回も検証で画面ショットに多少の変動がありますが、大まかに計算しているので無視していただければばと思います。
クラスタリソースの割合
アドミッショコントロール設定
まずクラスタリソースの割合から確認していきます。「クラスタリソースの割合(%)」を選択し後はデフォルト状態です。デフォルトではクラスタで許容するホスト障害「1」で設定します。
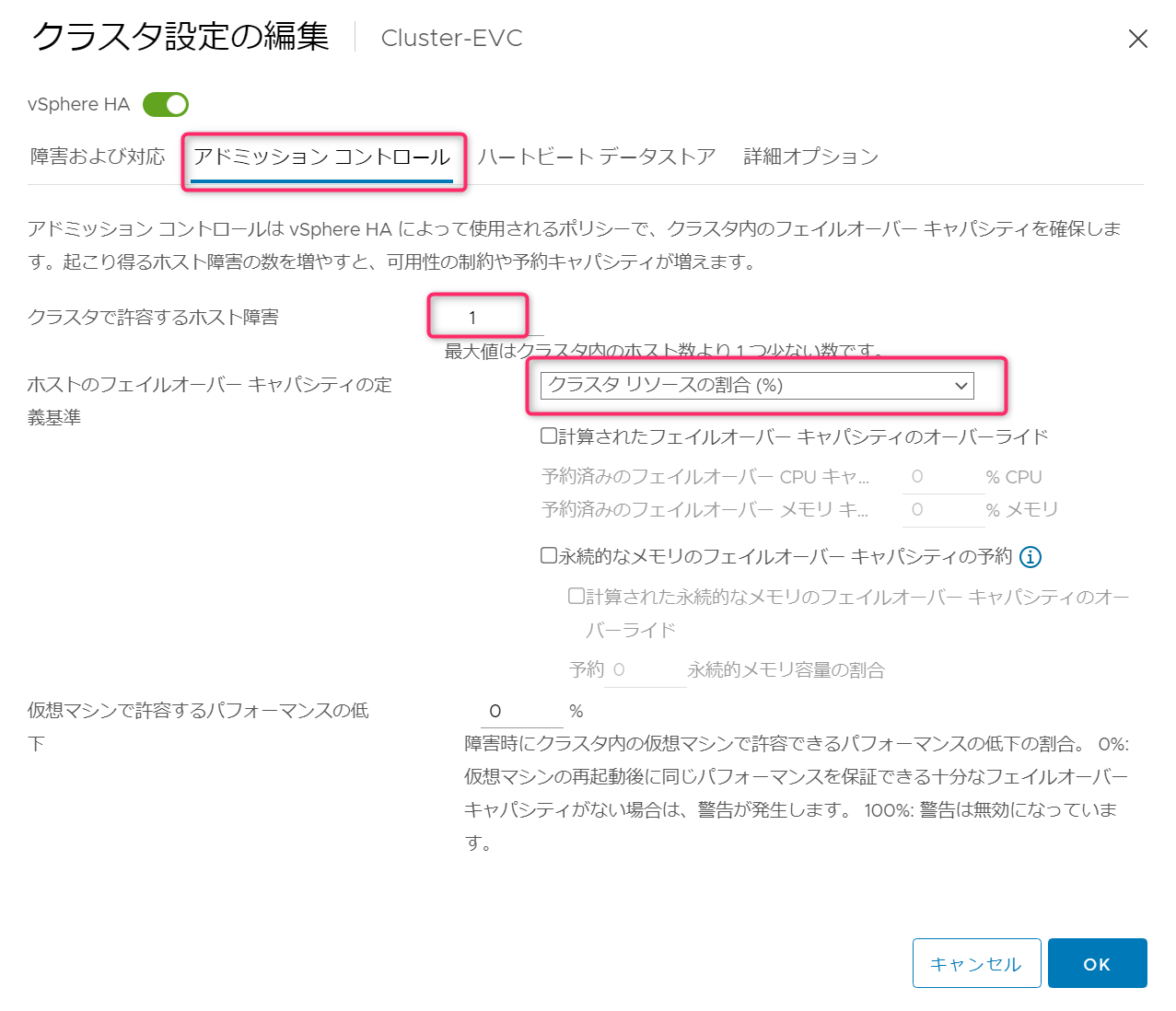
アドミッションコントロールとみるとCPUとメモリのキャパシティ(フェイルオーバー時に確保するリソース)として33%が自動で指定されています。これはホスト3台のうち障害の許容を1台にしているため100% / 3ホスト = 33%になっています。
クラスタのサマリ画面でも確認が行えます。
リソース確保のされ方
この時点のリソースの状況は、下記のようになっています。
クラスタのサマリで置き換えると下記のような状況です。

この後は、仮想マシンのリソース予約が67%までは、パワーオンなどの操作には制限がかからなくなります。仮想マシンに予約をしていない場合は、CPU予約は32MHz、メモリ予約は0MBとして扱われます。


vSphere HA では、仮想マシンの実際の予約が使用されます。仮想マシンに予約がない、つまり予約が 0 の場合は、デフォルトの 0MB のメモリおよび 32MHz の CPU が適用されます。
なお、メモリ予約は0MBとして扱われますが、仮想マシンを動かすためのメモリオーバーヘッド(十数MB~数百MB)は評価対象となります。
パワーオン状態の各仮想マシンのメモリ予約 (およびメモリ オーバーヘッド) を合計することによる、メモリ コンポーネントの値。
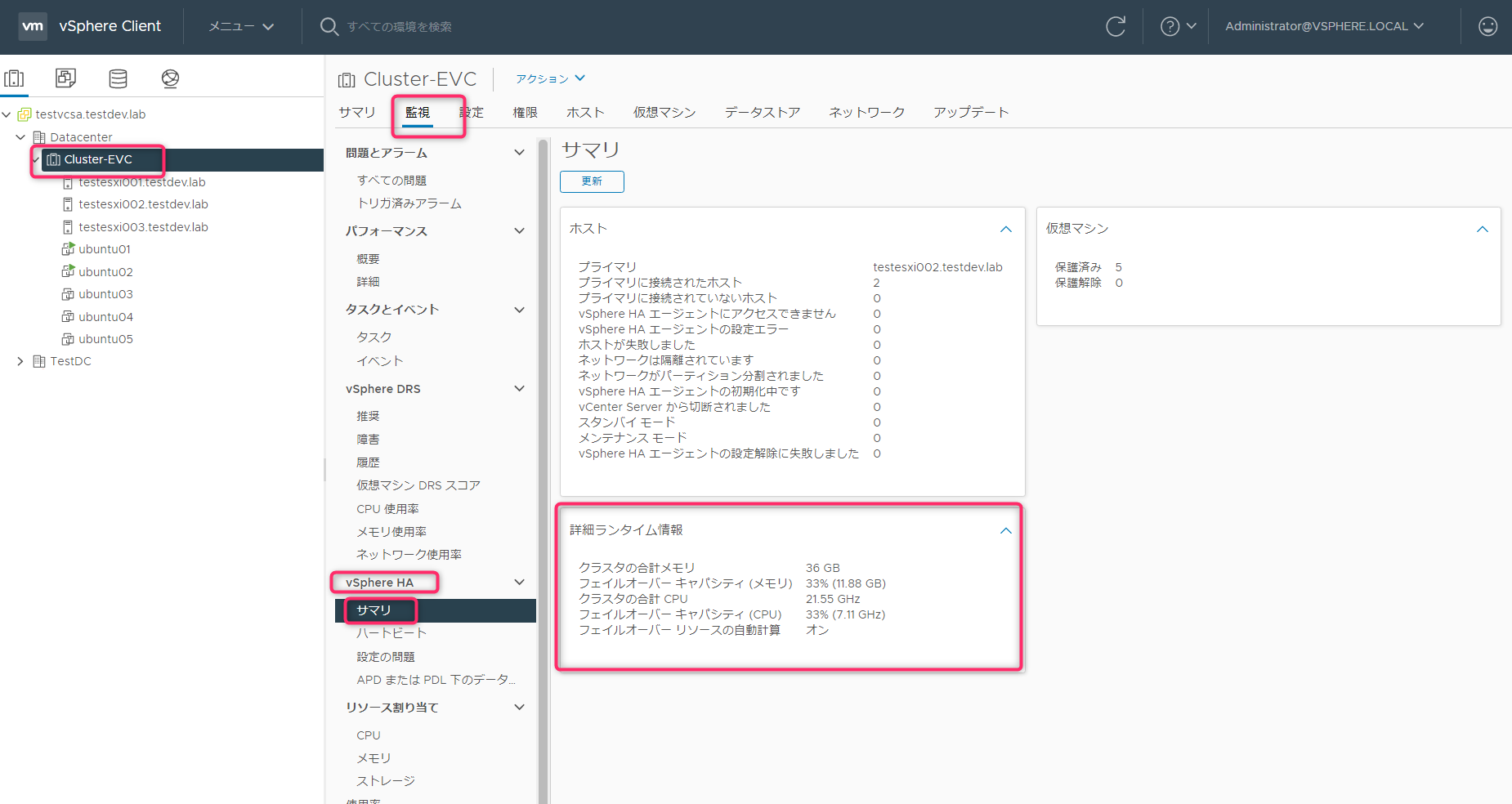
「クラスタ」->「監視」->「vSphere HA」->「サマリ」->「詳細ランタイム情報」でキャパシティの計算結果が簡易的に見えるのですが、33%がルートリソースプールではなく、物理リソースから計算されているため誤差が生じています。検証結果からも、本記事の計算方式が正しく、こちらに表示される計算結果は誤りと思われます。
仮想マシンの予約状況
| 仮想マシン | CPU予約 | メモリ予約 | 備考 |
| ubuntu01 | 0GHz | 4096MB | |
| ubuntu02 | 0GHz | 4096MB | |
| ubuntu03 | 0GHz | 4096MB | |
| ubuntu04 | 0GHz | 4096MB | |
| ubuntu05 | 0GHz | 0MB | 予約なし |
アドミッションコントロールが有効に効いているか確認するために上記のような予約を割り当てました。メモリの予約だけで確認を行います。
起動確認
想定する動作

ubuntu01から順番に起動していくと仮想マシンとして利用できる15.3GBの仮想マシン(ubuntu04)を起動するときに制限がかかるはずです。
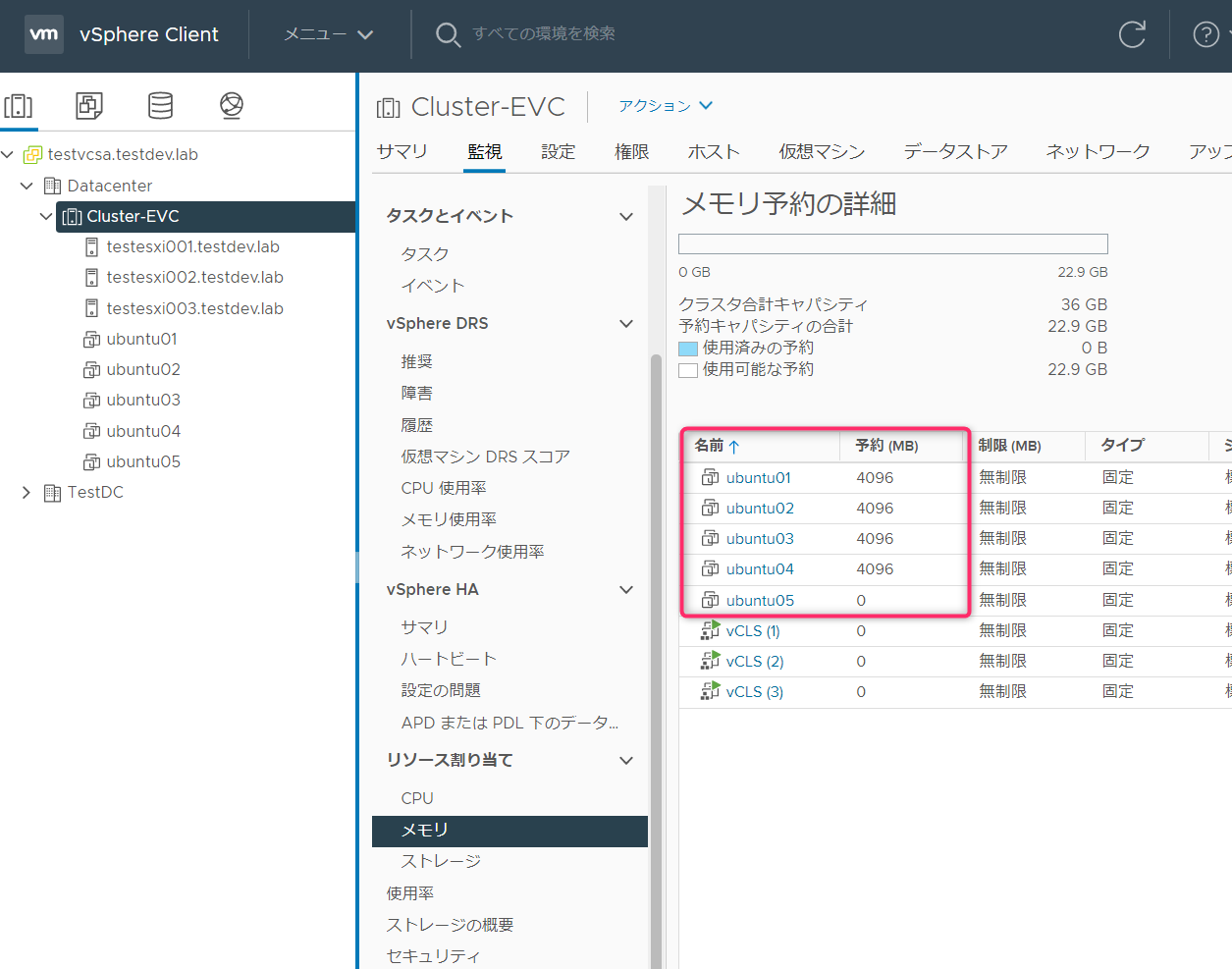
Ubuntu01起動(メモリ予約4GB)
Ubuntu01を起動しました。ここで使用済みの予約が11.63GBまで跳ね上がりました。
これは、クラスタ内の1台目の仮想マシンが起動するタイミングで、仮想マシンのメモリ予約(4GB)とクラスタキャパシティの33%(7.56GB)の両方が使用済みの予約としてカウントされるためかと思われます。
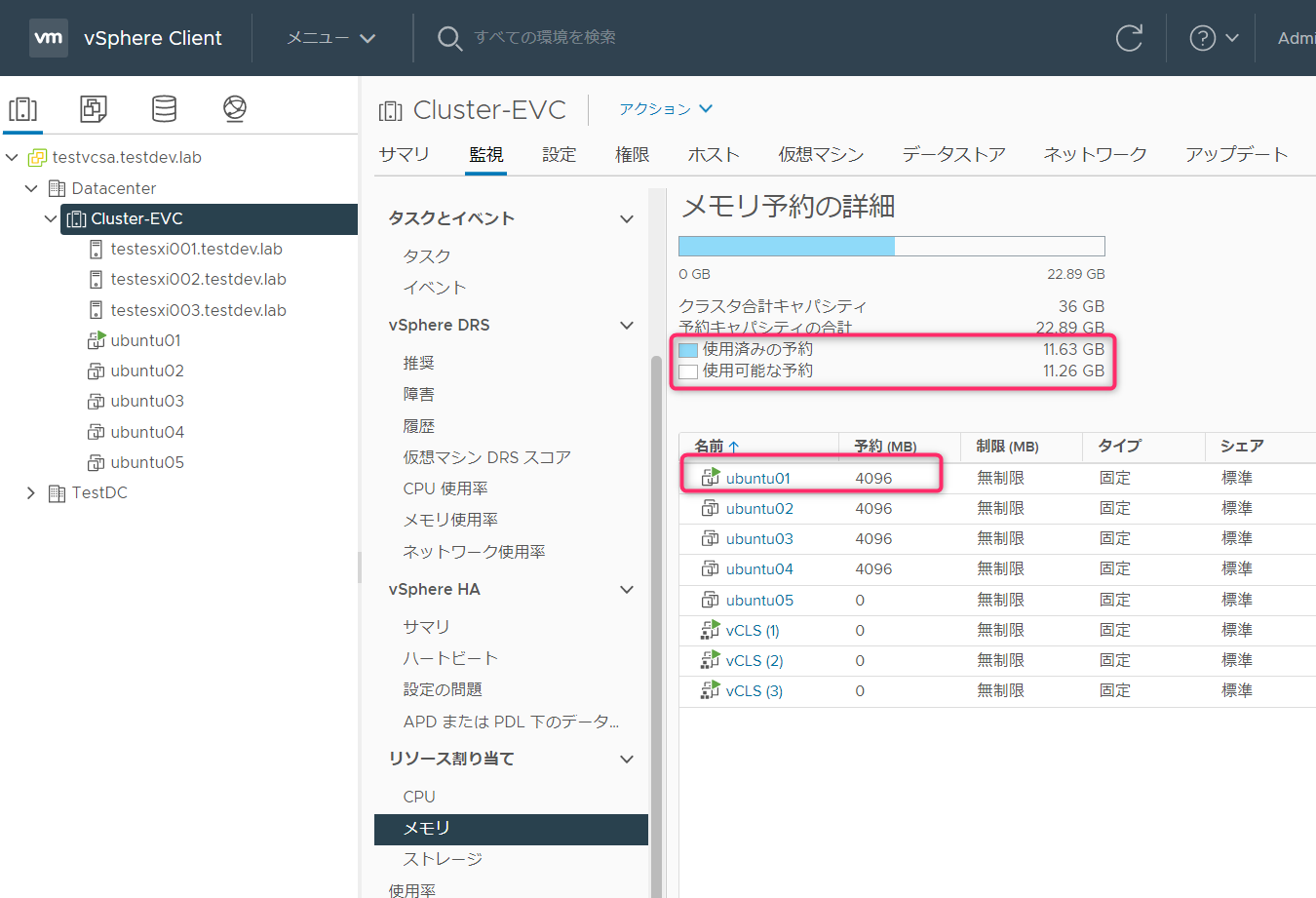
Ubuntu02起動(メモリ予約4GB)
Ubuntu02も正常に起動しました。メモリ予約の4GB分が使用済み予約に追加されました。
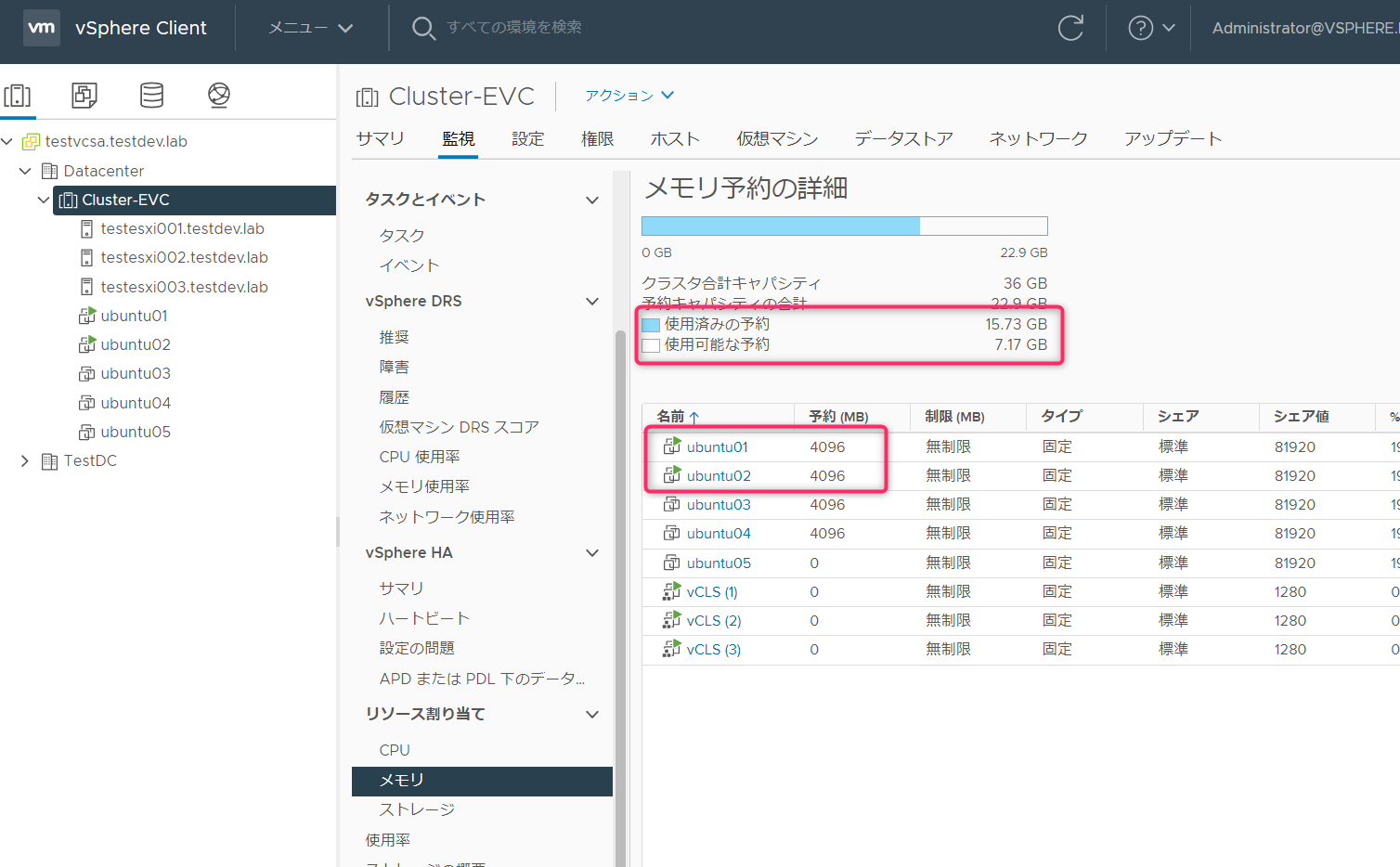
Ubuntu03起動(メモリ予約4GB)
Ubuntu03を起動しました。メモリ予約の4GB分が使用済み予約に追加されました。この時点で使用可能な予約は3.06GBになっているので、メモリ予約が3.06GB以上(正確には、メモリオーバーヘッドも含む)稼働マシンは起動できないはずです。
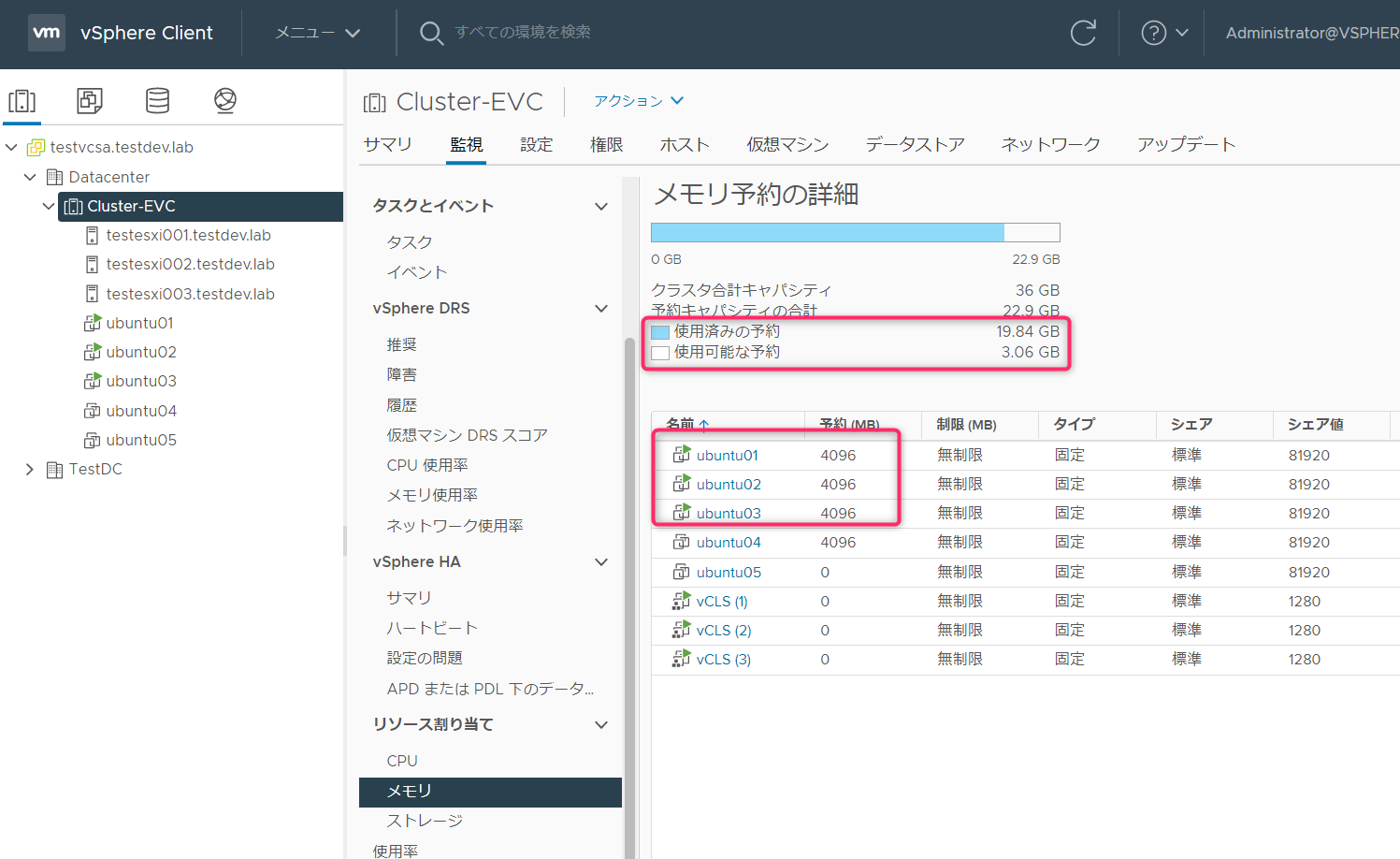
Ubuntu04起動(メモリ予約4GB)
Ubuntu04を起動すると「vSphere HAの設定済みフェイルオーバーレベルに十分なリソースがありません。」が表示され起動することはできません。
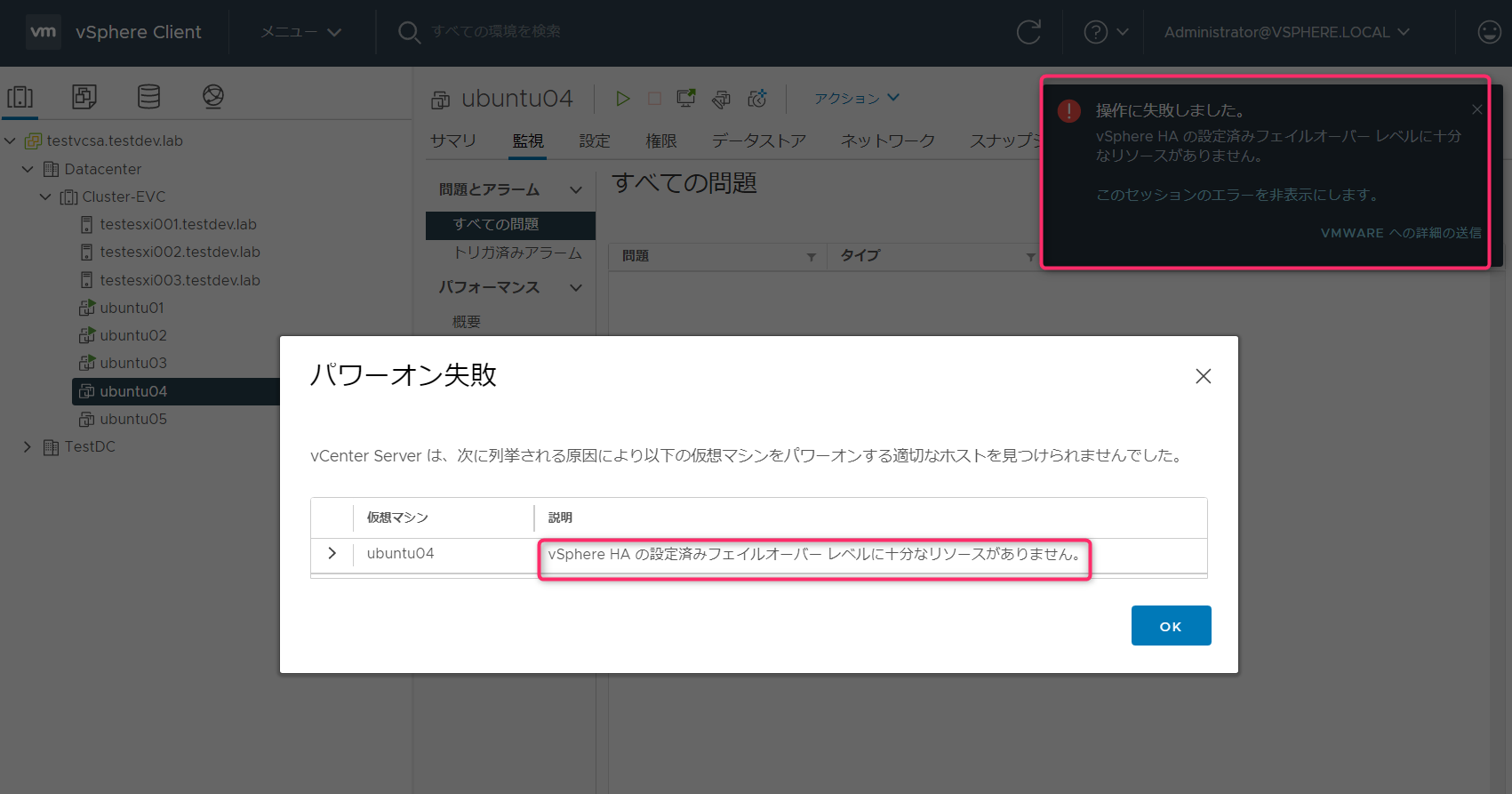
Ubuntu05起動(メモリ予約0MB)
Ubuntu05はメモリ予約がないため、起動が行えます。

予約は超えないが、実使用量が超えた場合
念のため仮想マシン全体でメモリ予約量は超えていないが、メモリの実使用量が超えている場合も確認してみました。
Ubuntu01,02を起動してStressコマンドで搭載メモリ8GBをすべて使いきってみます。
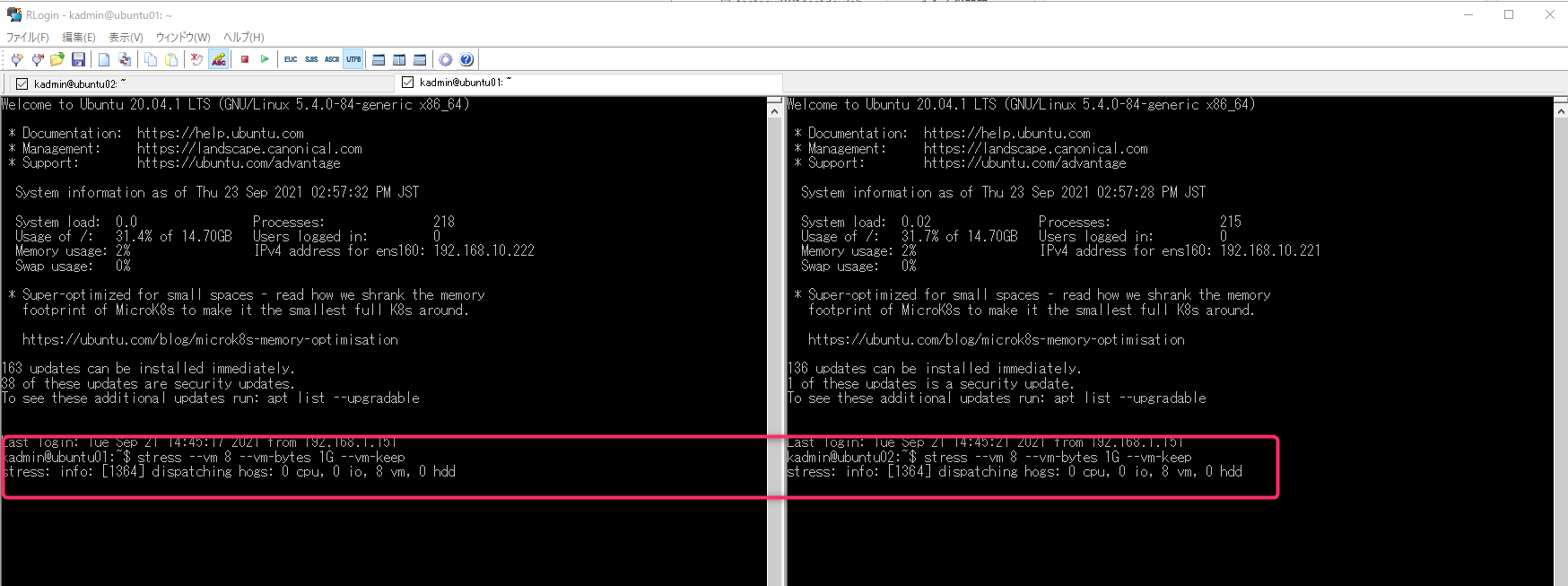
Ubunut01,02で計16GBのメモリを消費しています。
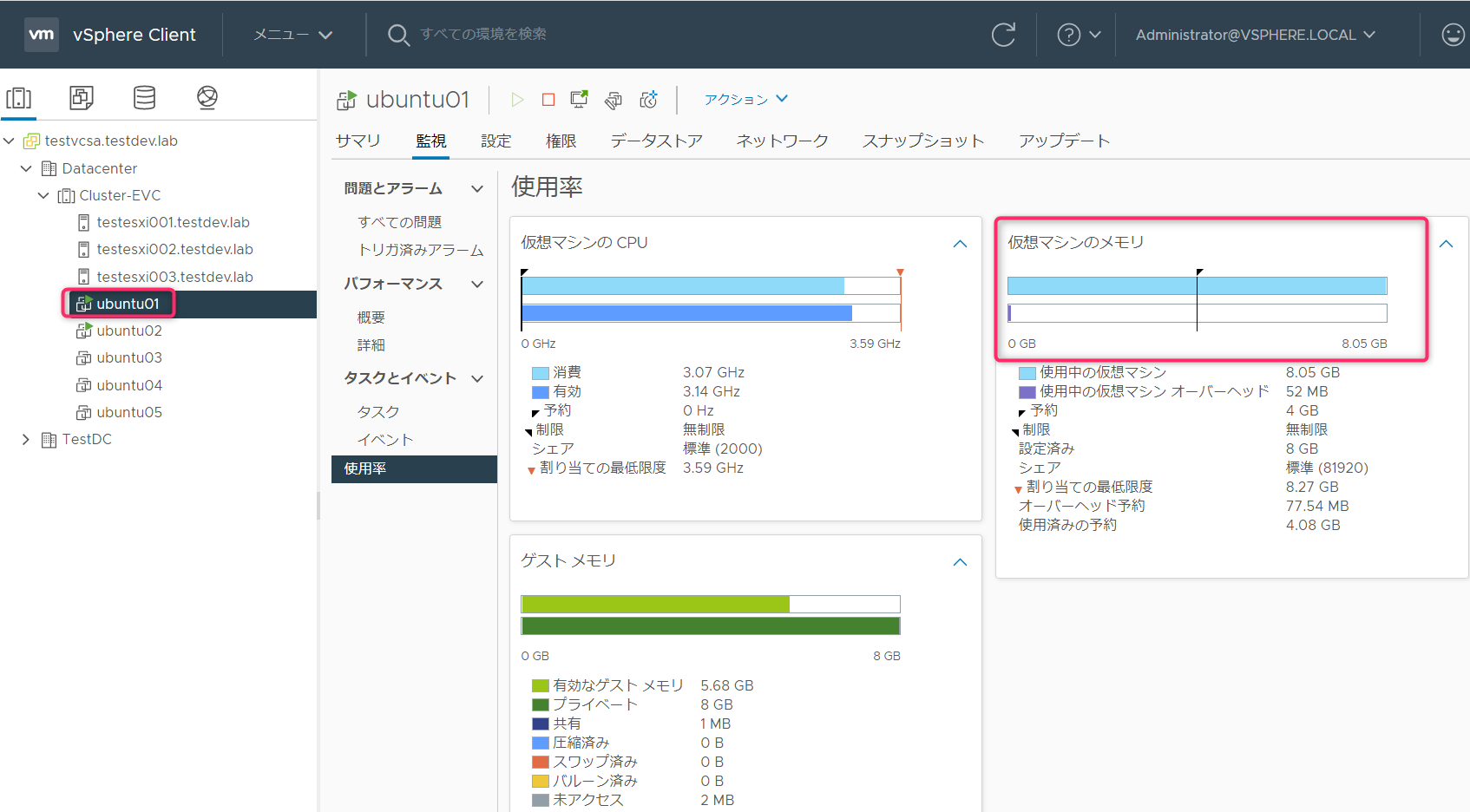
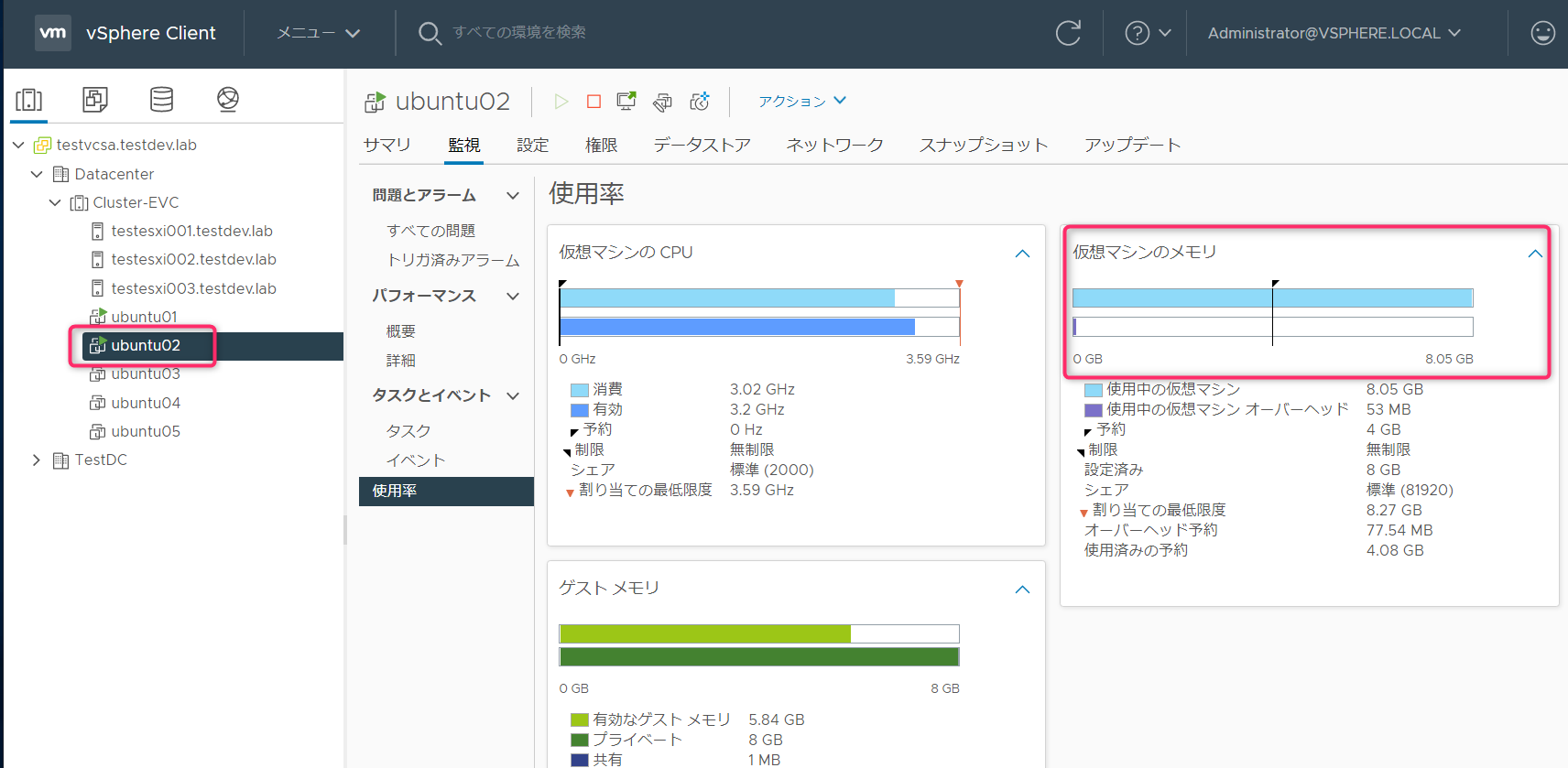
実消費量はアドミッションコントロールの評価対象とはならないため、メモリ予約4GBを設定しているUbuntu03を起動することができます。
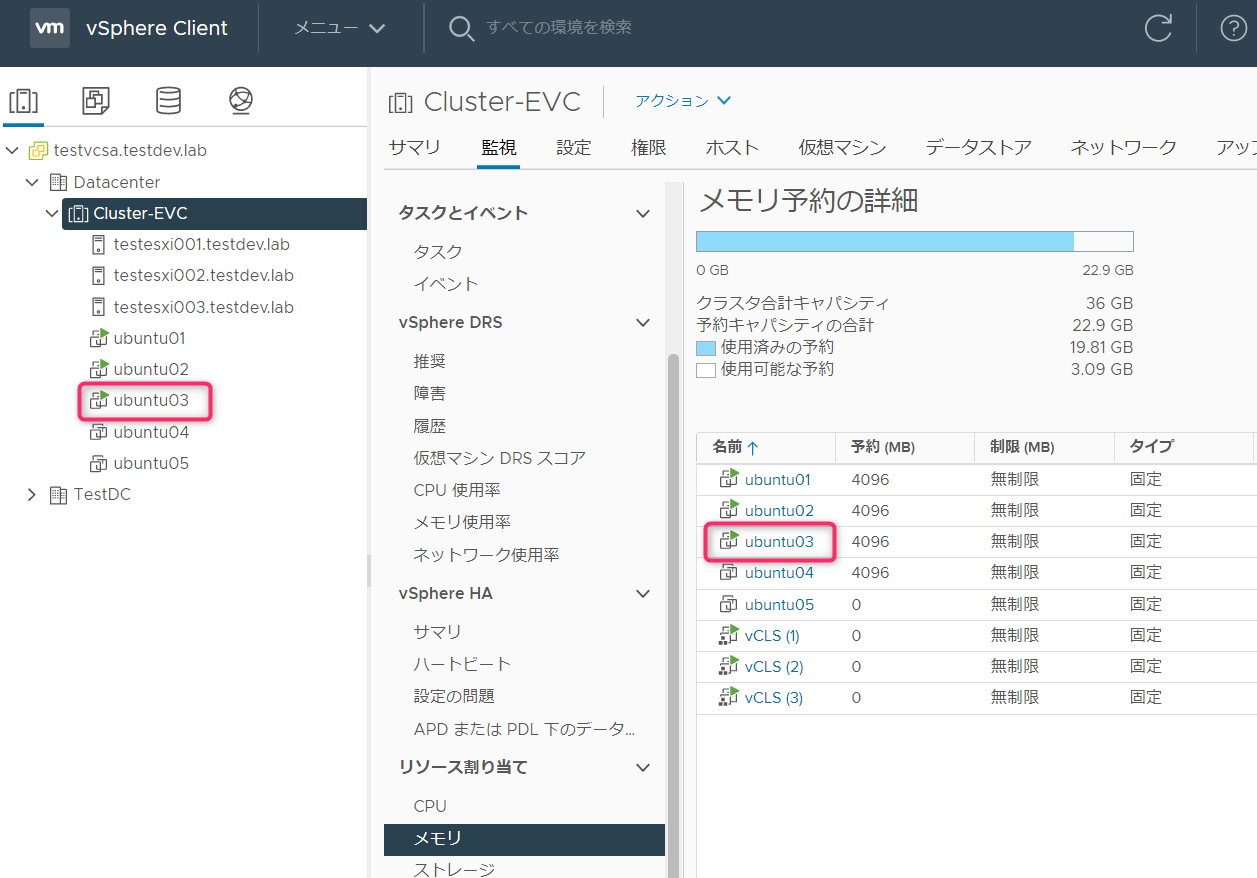
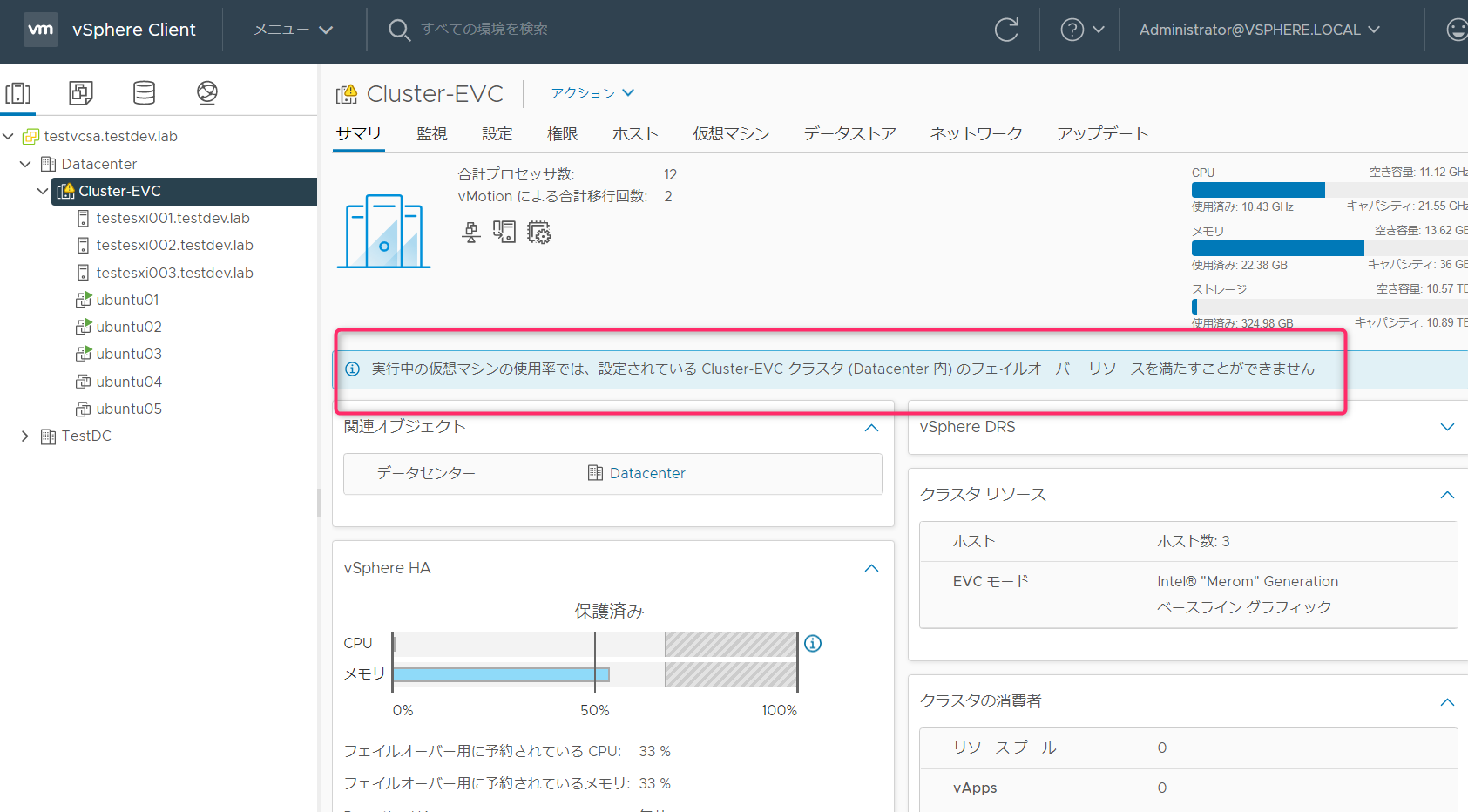
予約が超えなければ、パワーオンなどの制限はかかりませんがクラスタで「実行中の仮想マシンの使用率では、設定されている<クラスタ名>のフェイルオーバーリソースを満たすことができません」との警告が表示されます。
スロットポリシー
アドミッショコントロール設定
「スロットポリシー(パワーオン状態の仮想マシン)」を選択し後はデフォルト状態です。デフォルトではクラスタで許容するホスト障害「1」で設定します。
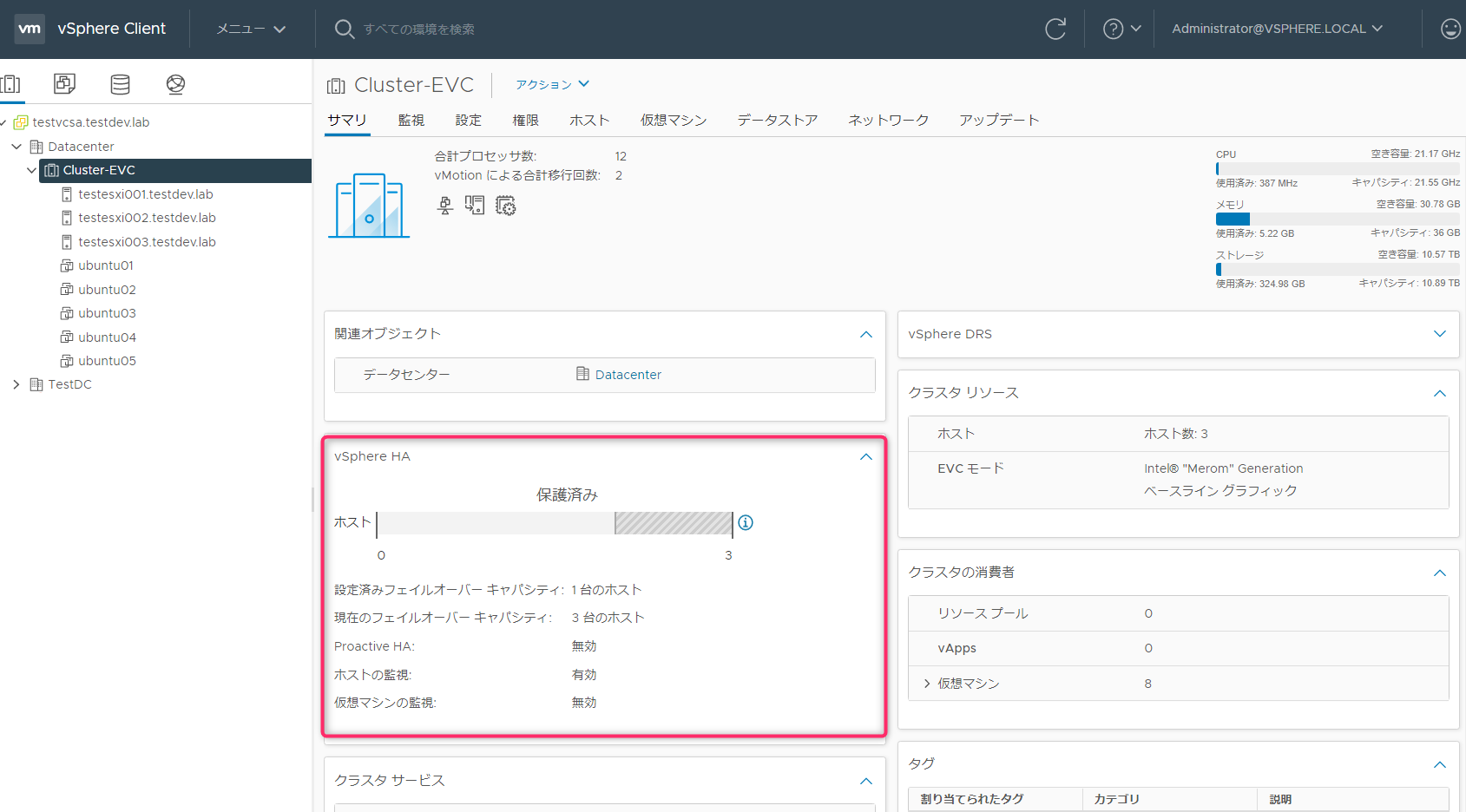
アドミッションコントールを見ると設定されていることがわかります。クラスタリソースのように数値などは表示されていません。

クラスタのサマリ画面でも確認が行えます。こちらもクラスタリソースのように数値などは表示されていません。
リソース確保のされ方

スロットポリシーはのリソースの確保の考え方は一番難しいと感じます。
スロットとは、ホスト1台あたりに稼働できる仮想マシンの台数の単位を表します。画像のようにホスト1台1スロットでばれ、クラスタ内にホスト3台があるためクラスタ全体で3スロットになります。ホスト1台の障害を許容している場合は、3スロット-1スロット=2スロットとなりクラスタで2スロット(仮想マシン2台)が稼働できます。
スロットの計算は、クラスタ内で起動状態の仮想マシンのCPUとメモリ予約の最大のものを取得し、ルートリソースプールをホスト台数で割った値を仮想マシンのCPU、メモリ予約値で割り小数点を切捨てた値がスロットサイズになります。


仮想マシンのCPU、メモリ予約がされていない場合、CPU予約は32MHz、メモリ予約は0MBとして扱われます。クラスタリソースと同じくメモリオーバーヘッドは評価対象になります。
vSphere HA では、パワーオン状態の各仮想マシンの CPU 予約を取得し、最も大きな値を選択することによって、CPU コンポーネントを計算します。仮想マシンの CPU 予約を指定していない場合、デフォルト値である 32MHz が割り当てられます。das.vmcpuminmhzという詳細オプションで、この値を変更できます。
vSphere HA では、パワーオン状態の各仮想マシンのメモリ予約 (にメモリ オーバーヘッドを加えた値) を取得し、最も大きな値を選択することによって、メモリ コンポーネントを計算します。メモリ予約には、デフォルト値はありません。
なお、ホストのCPU、メモリのスペックが異なる場合は、スロットが一番大きなものから障害が発生した場合残りのスロット数が稼働可能な仮想マシン台数になります。
現在のフェイルオーバー キャパシティは、何台のホスト (最も大きいものから開始) で障害が発生する可能性があるか、およびパワーオン状態のすべての仮想マシンの要件を満たす十分なスロットが残っているかを判定することによって計算されます。
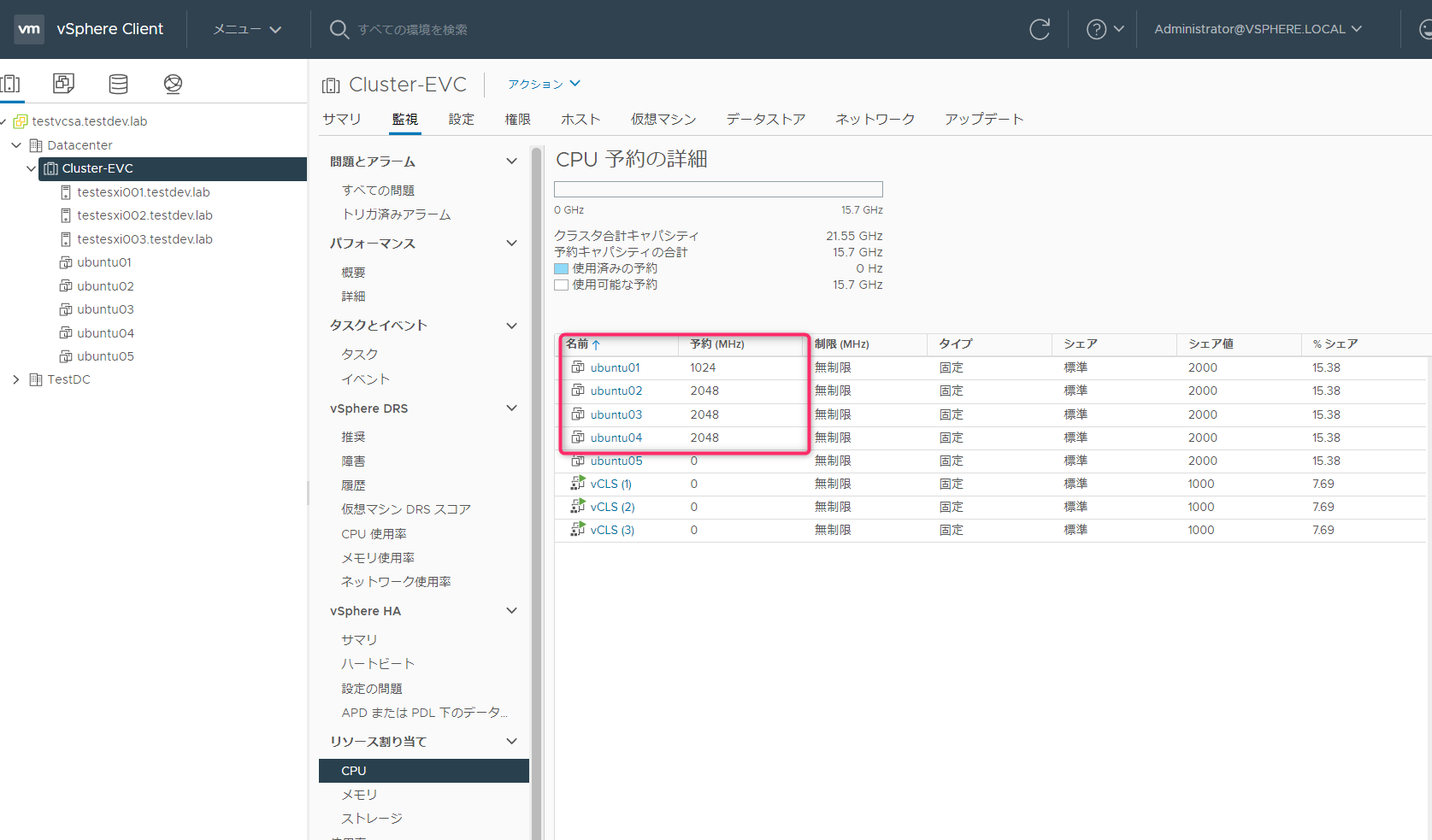
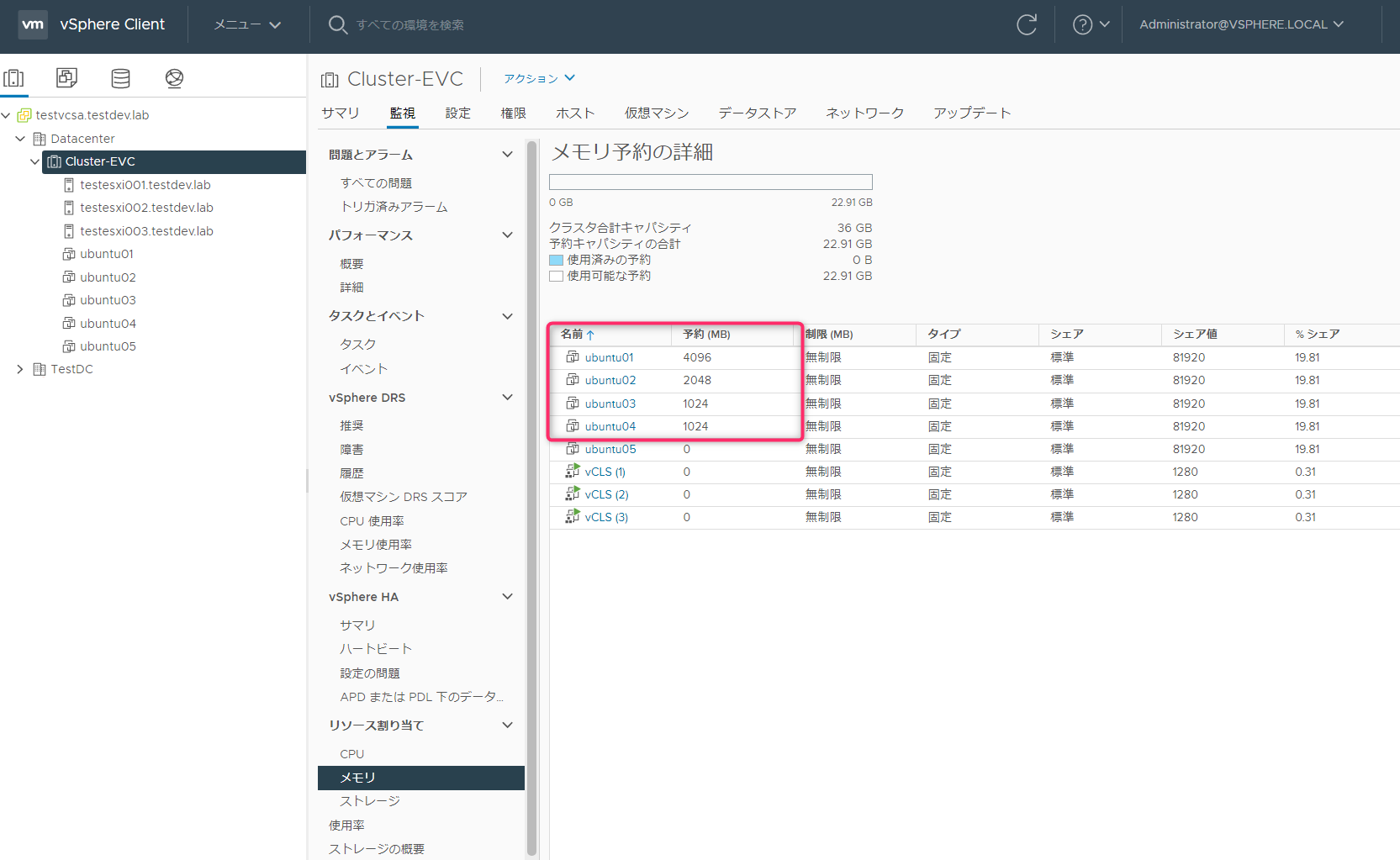
仮想マシンの予約状況
| 仮想マシン | CPU予約 | メモリ予約 | 備考 |
| ubuntu01 | 1024GHz | 4096MB | |
| ubuntu02 | 2048GHz | 2048MB | |
| ubuntu03 | 2048GHz | 1024MB | |
| ubuntu04 | 2048GHz | 1024MB | |
| ubuntu05 | 0GHz | 0MB | 予約なし |
アドミッションコントロールが有効に効いているか確認するために上記のような予約を割り当てました。
起動確認
想定する動作
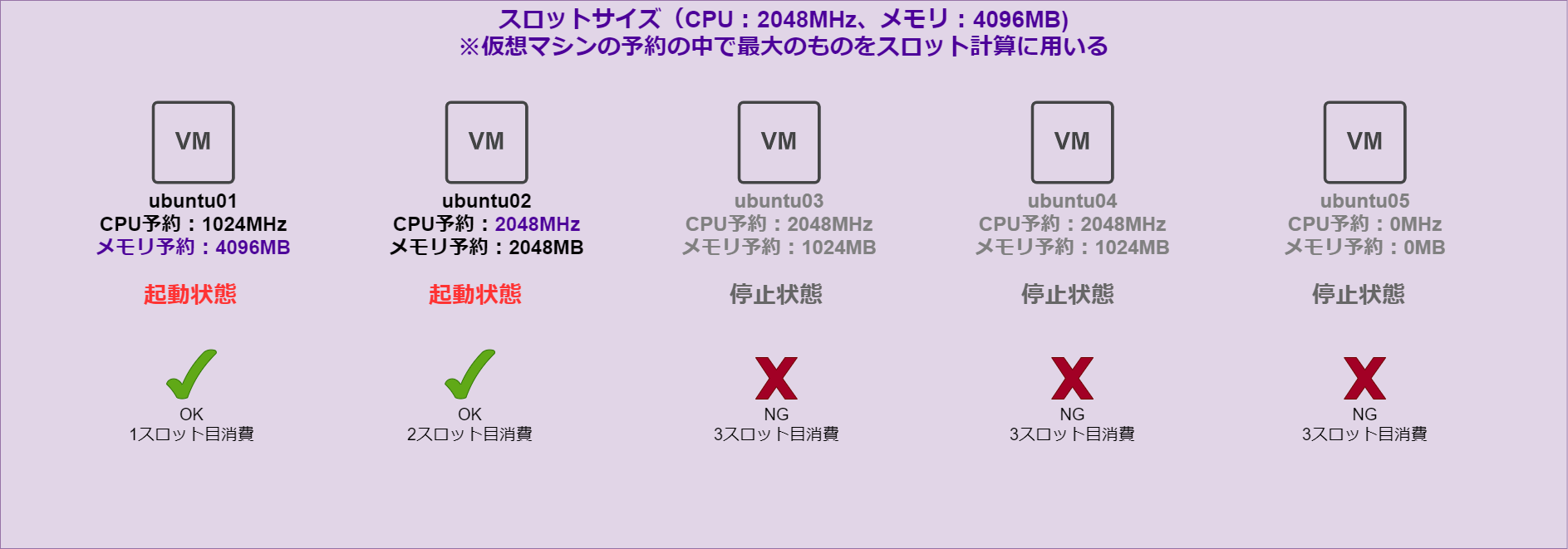
Ubuntu01から順番に起動していくと、Ubuntu02の起動完了後には、クラスタ内で2スロット(仮想マシン2台)までしか稼働できないことが確定します。その後、3スロット目を消費しようとするため稼働マシンの起動はすべて行えなくなります。
Ubuntu01起動(1スロット目消費)
Ubuntu01が起動できました。
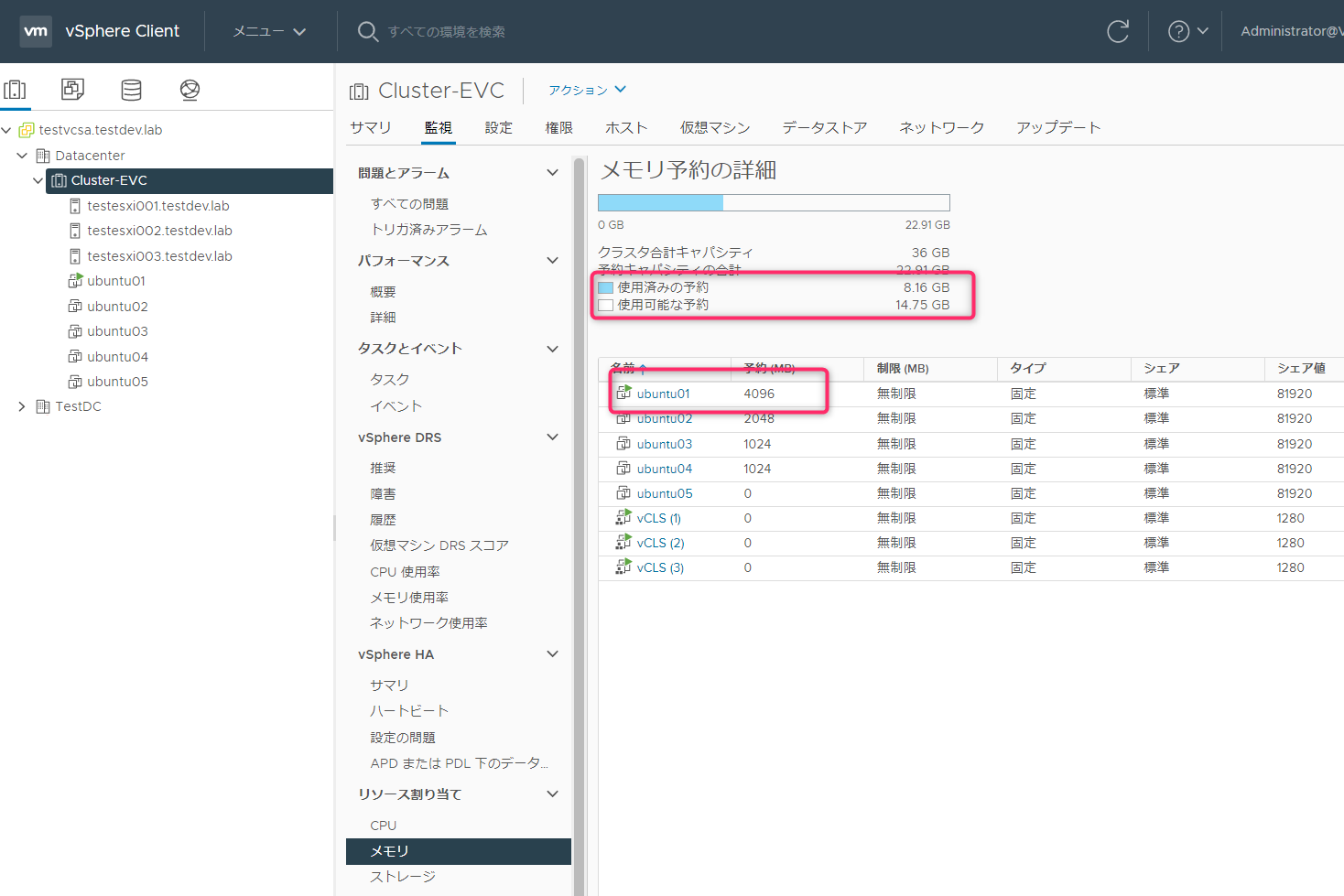
Ubuntu02起動(2スロット目消費)
Ubuntu02がで起動できました。この時点で使用可能な予約が12.67GBあります。
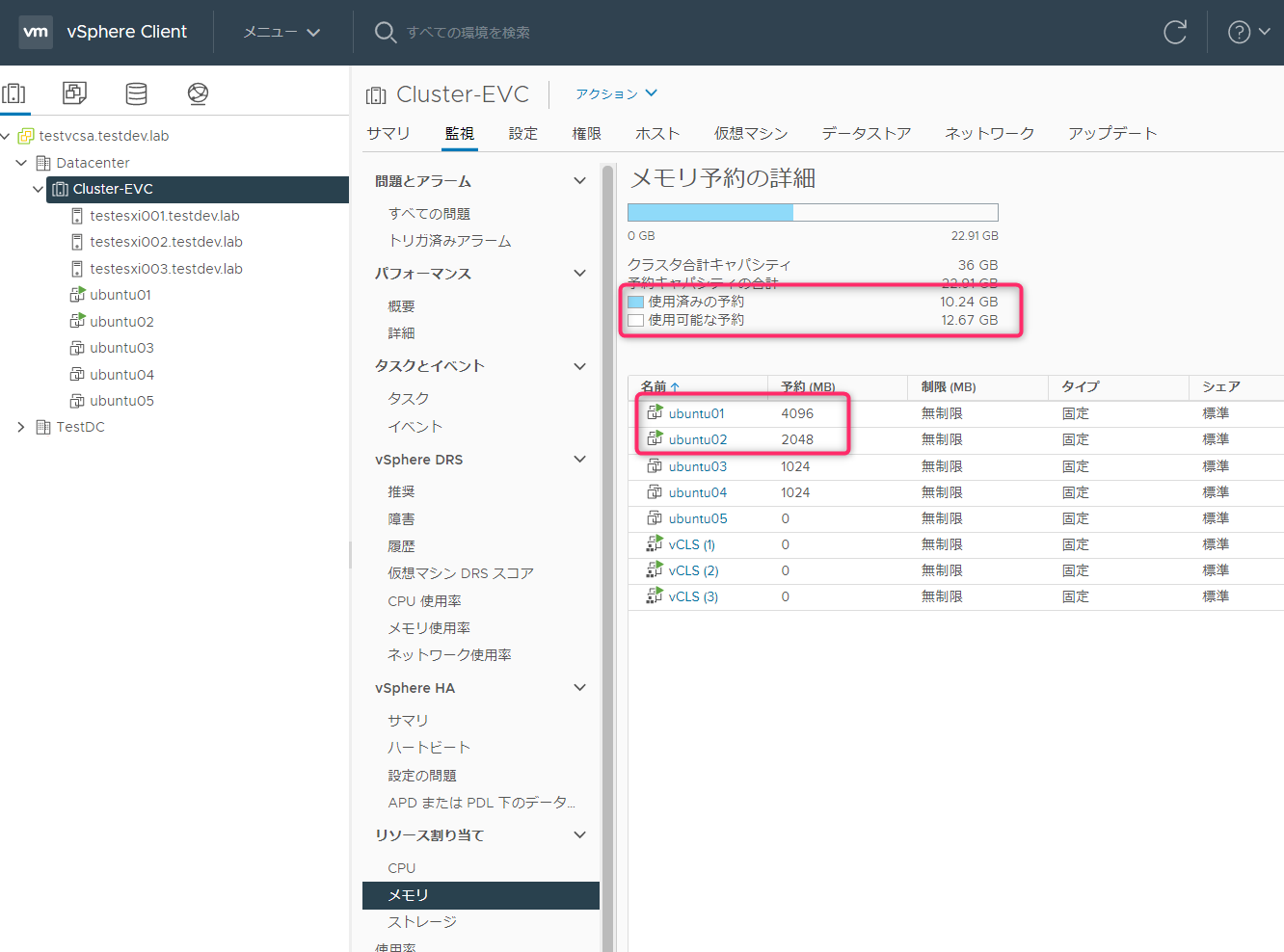
「クラスタ」->「監視」->「vSphere HA」->「サマリ」->「詳細ランタイム」を見ると、使われているスロットサイズやスロット数の詳細を確認できます。
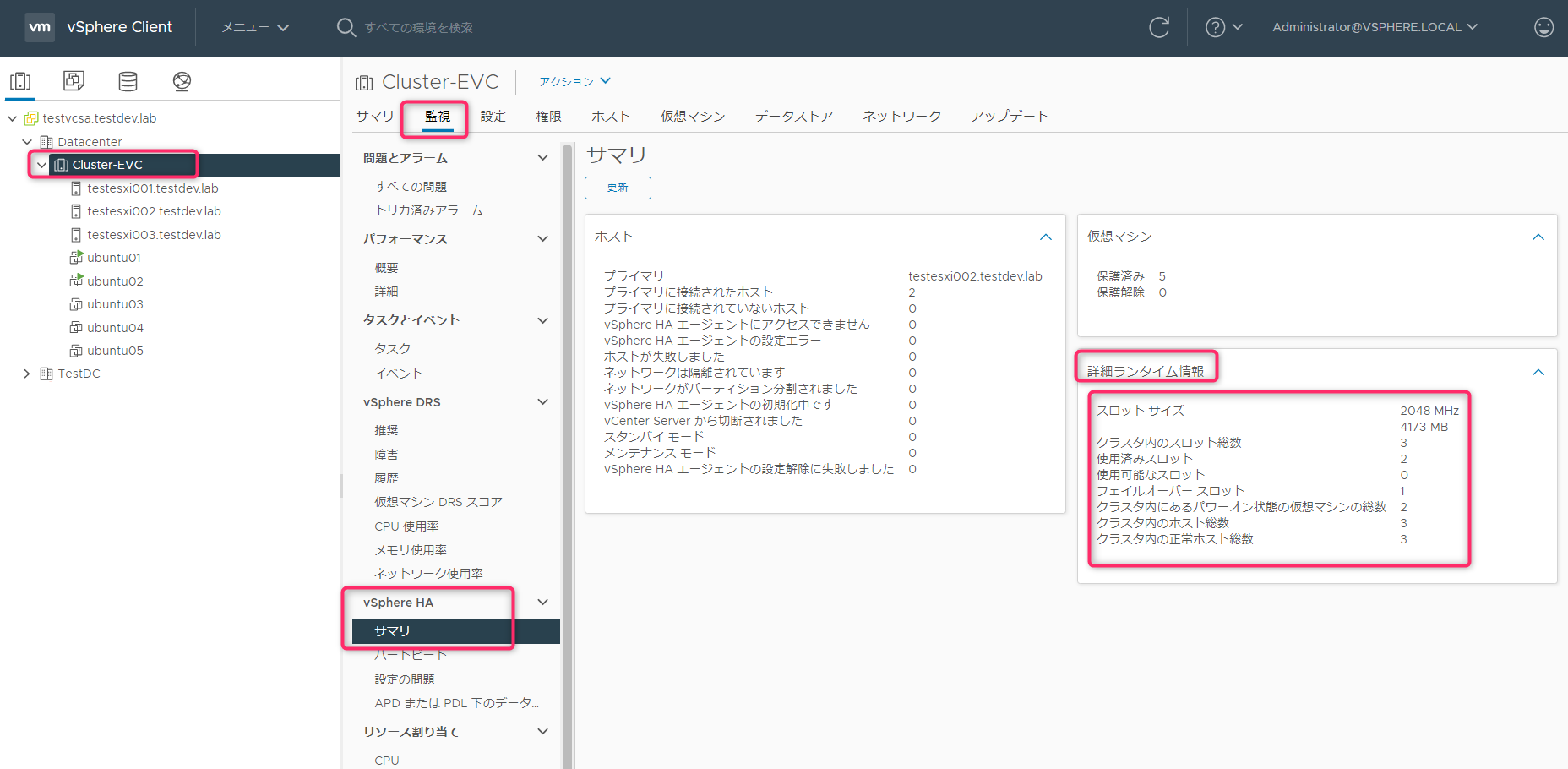
Ubuntu03起動(3スロット目を消費しようとする)
3スロット目を消費しようとすると「vSphere HAの設定済みフェイルオーバーレベルに十分なリソースがありません。」が表示され起動することはできません。
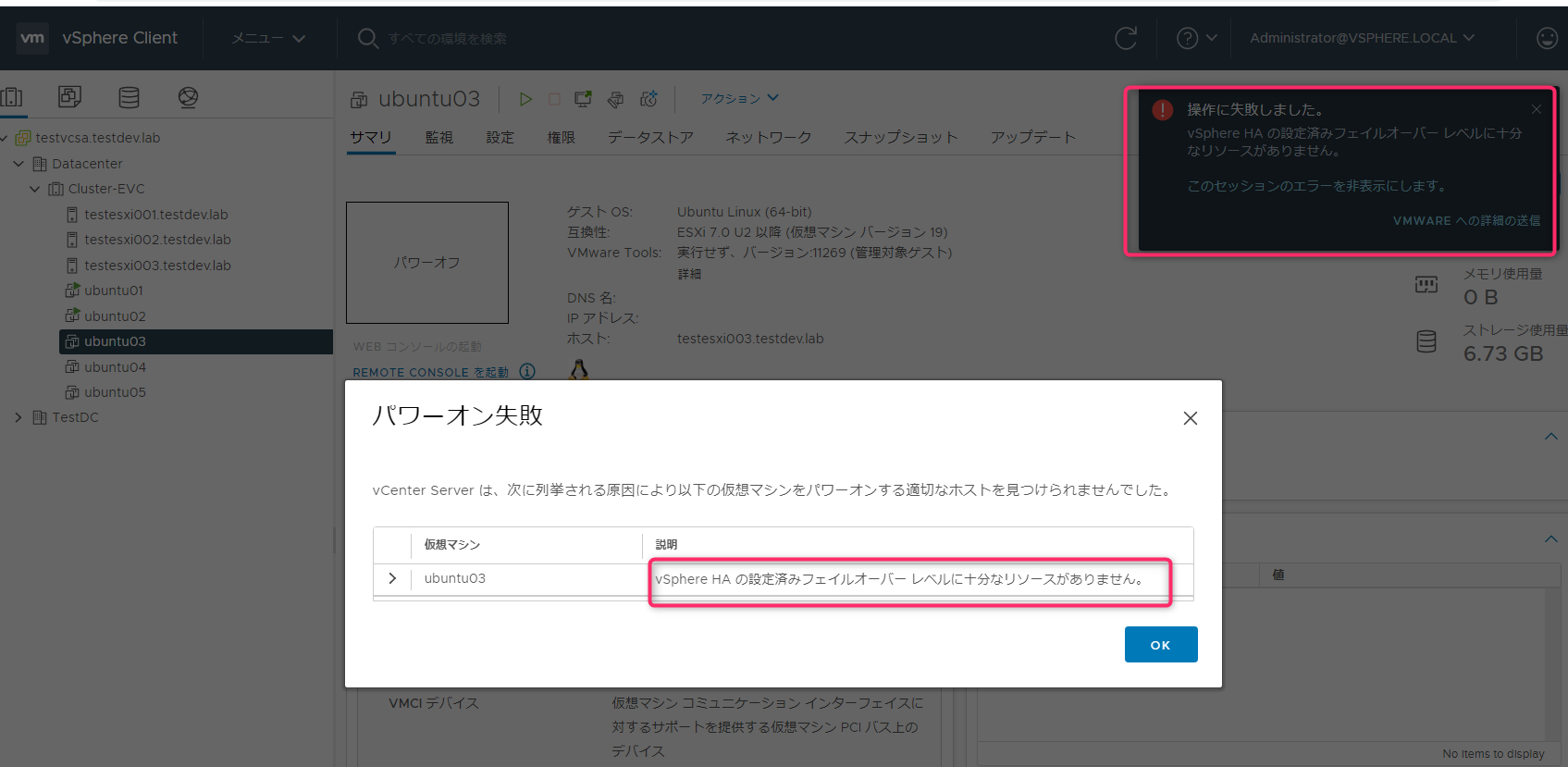
Ubuntu04起動(3スロット目を消費しようとする)
3スロット目を消費しようとすると「vSphere HAの設定済みフェイルオーバーレベルに十分なリソースがありません。」が表示され起動することはできません。
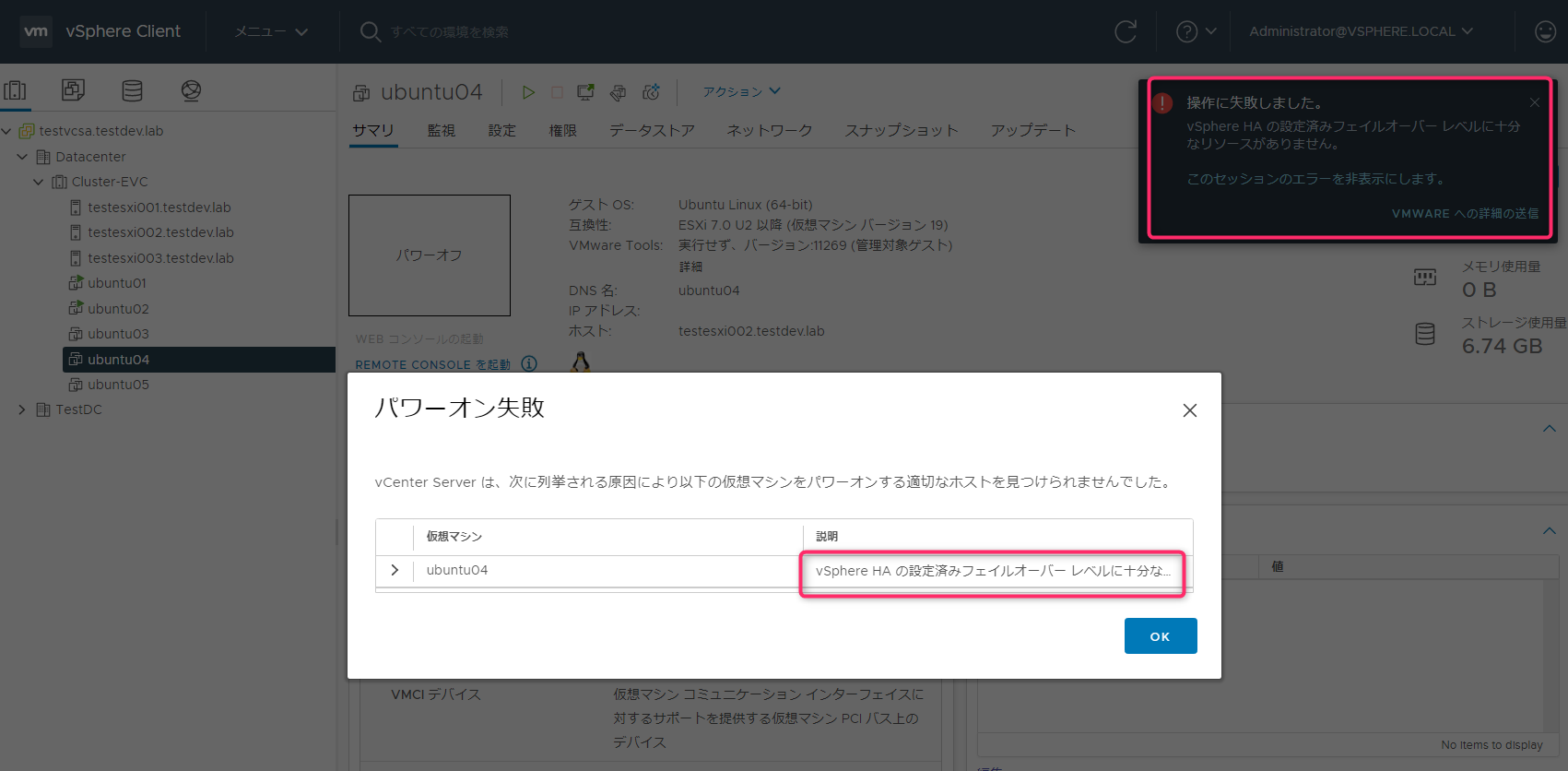
Ubuntu05起動(3スロット目を消費しようとする)
3スロット目を消費しようとすると「vSphere HAの設定済みフェイルオーバーレベルに十分なリソースがありません。」が表示され起動することはできません。CPU、メモリを予約していなかったとしても、Ubuntu01、02の起動状態でスロット数が2と確定しているため、ルートリソースプールが余っていても、スロットポリシーに違反してしまうため制限されます。
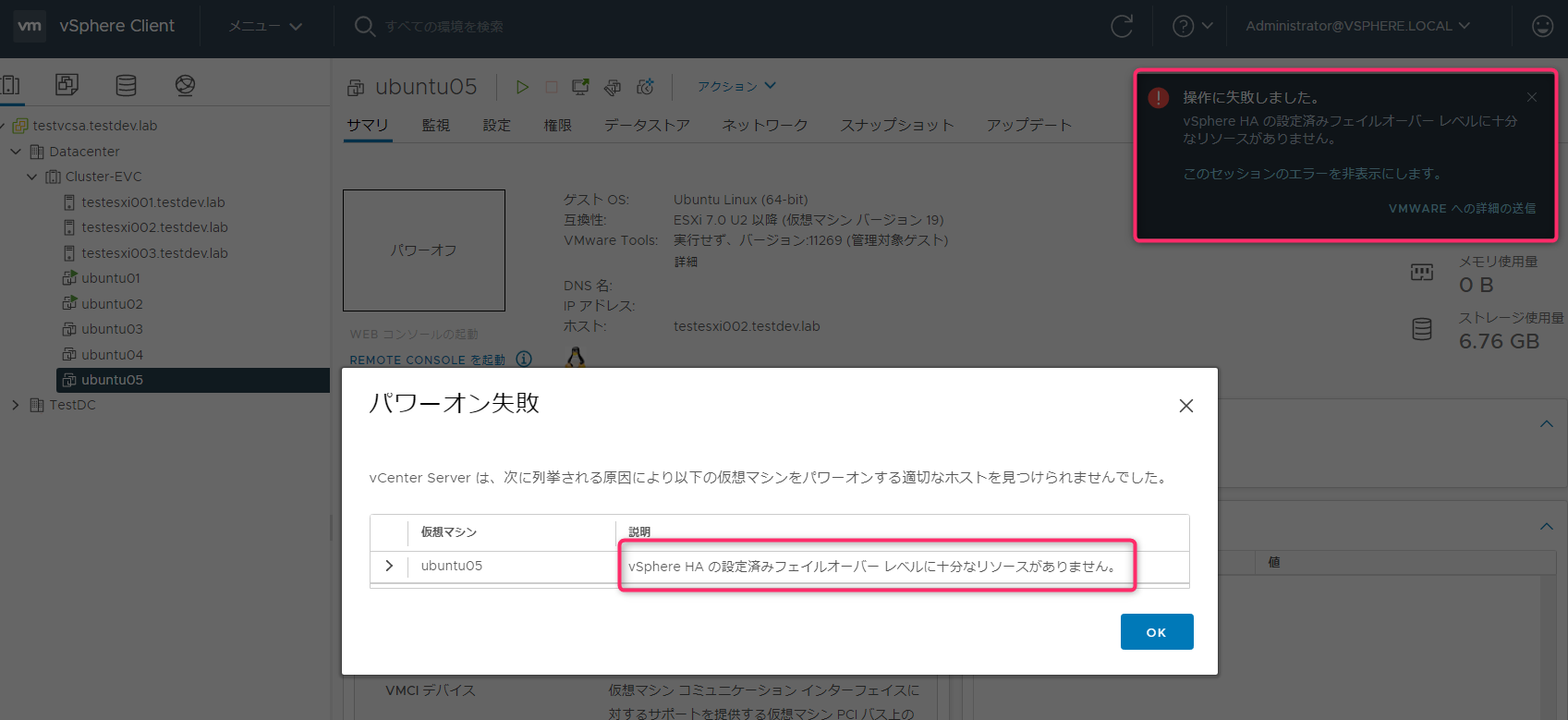
専用フェイルオーバーホスト
アドミッショコントロール設定
「専用フェイルオーバーホスト」を選択し、フェイルオーバーホスト欄にホストを追加します。他はデフォルト状態です。デフォルトではクラスタで許容するホスト障害「1」で設定します。
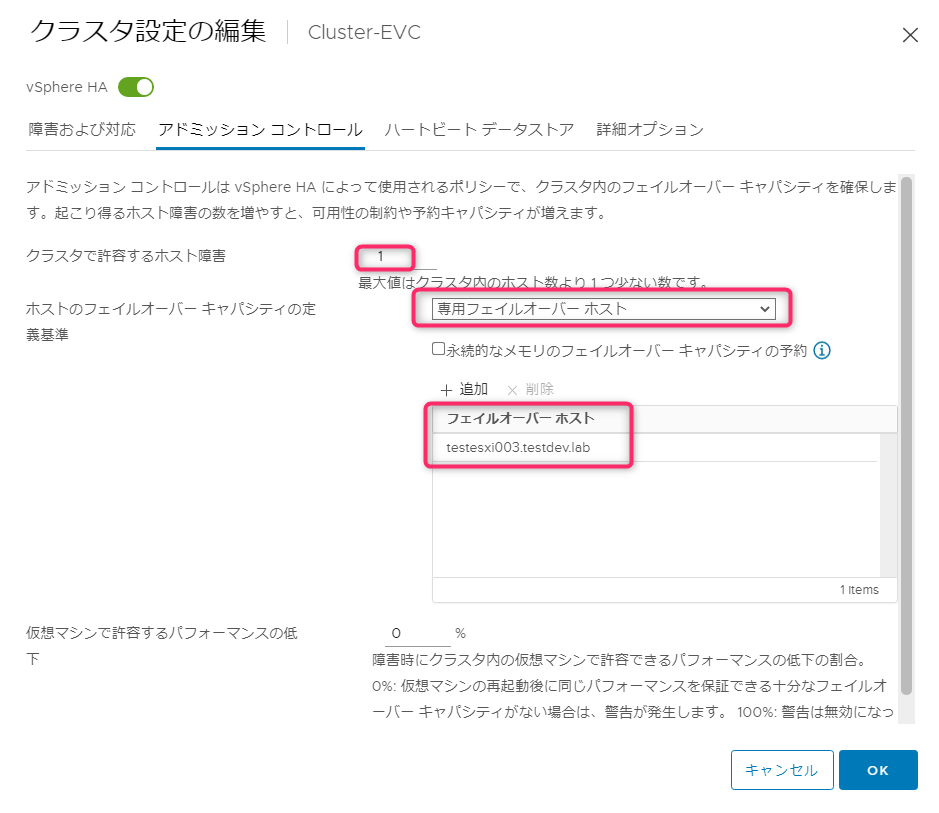
アドミッションコントールを見ると設定されていることがわかります。クラスタリソースのように数値などは表示されていません。
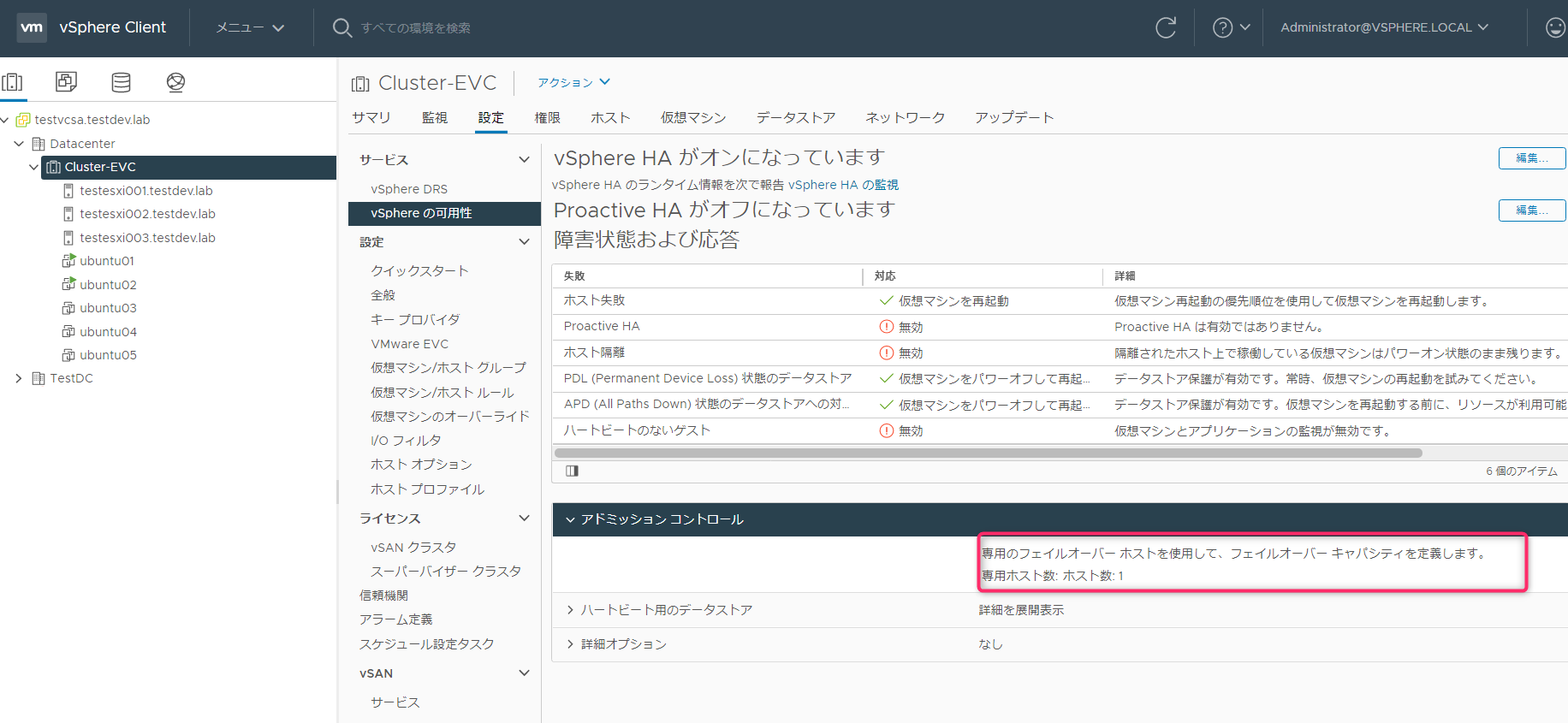
クラスタのサマリ画面でも確認が行えます。フェイルオーバーのキャパシティとして物理リソースになっていますが、アドミッションコントロールの評価対象はあくまでルートリソースプールになります。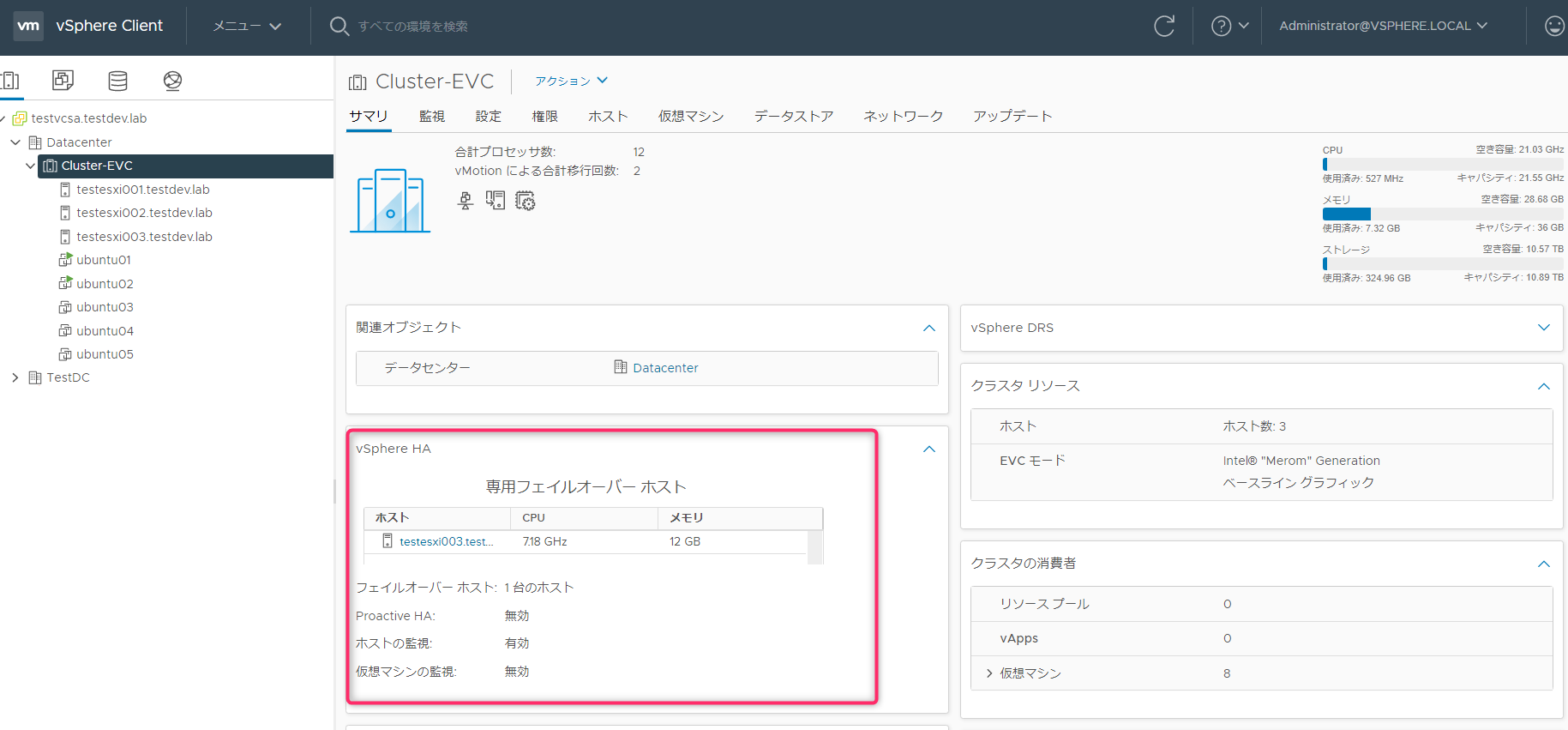
リソース確保のされ方
フェイルオーバーホストのリソース確保された方がドキュメントに記載がありませんでした。

検証した結果不確かな動きがあったので、備忘録として残しておきます。
フェイルオーバーホスト1台を指定しているため、ルートリソースプールを3分割した1台分がフェイルオーバーキャパシティとして確保されると考えていました。この図の計算方法は誤りであることがわかりました。
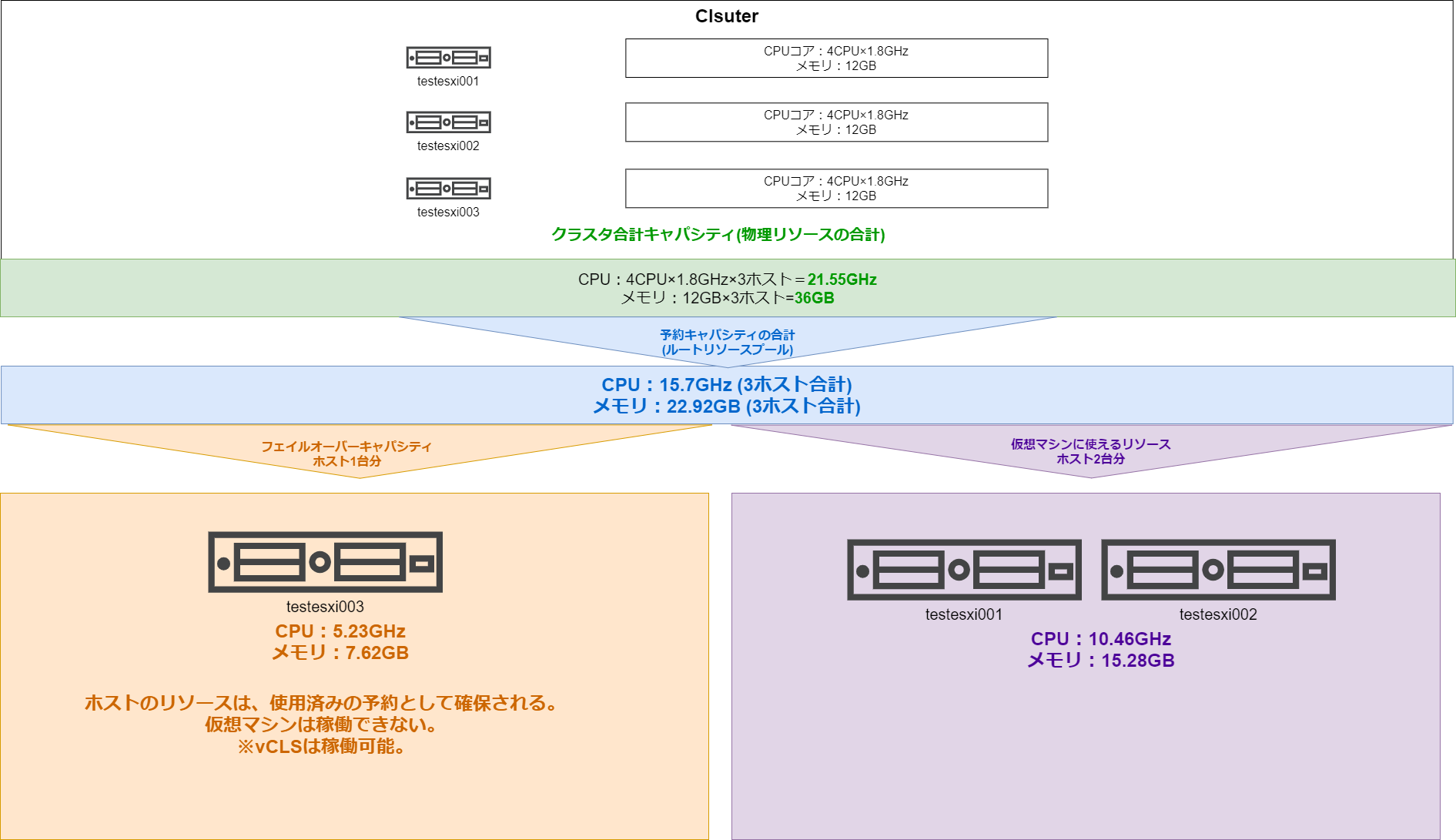
なぜ誤っているのか備忘録として残しておきます。
1ホスト分が使用済み予約として割り当てれます。
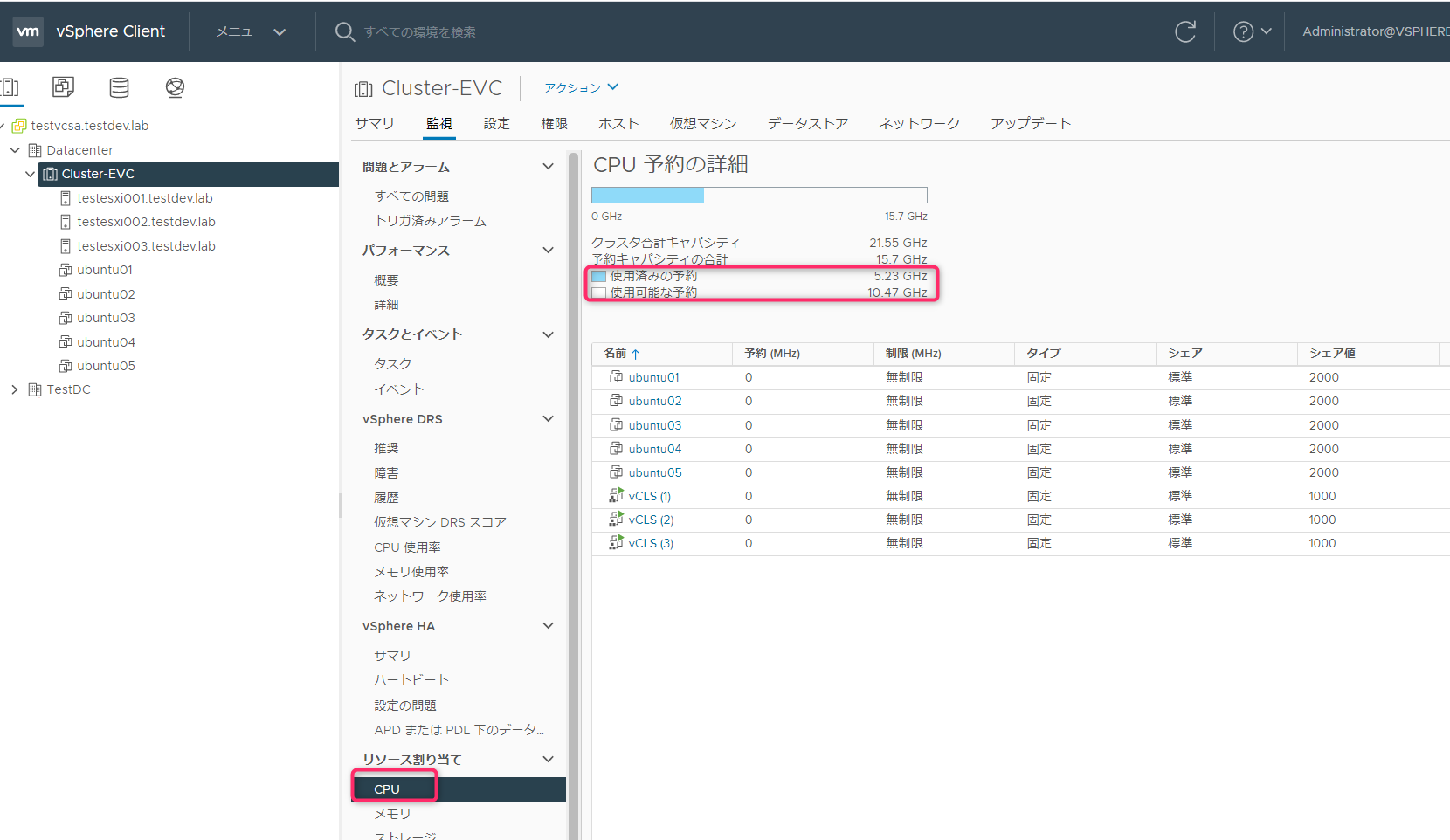
約1ホスト分が使用済みの予約として割り当てられます。※厳密な3分割から300MBほど誤差が発生しました。
仮想マシンの予約状況
| 仮想マシン | CPU予約 | メモリ予約 | 備考 |
| ubuntu01 | 0GHz | 4096MB | |
| ubuntu02 | 0GHz | 4096MB | |
| ubuntu03 | 0GHz | 4096MB | |
| ubuntu04 | 0GHz | 4096MB | |
| ubuntu05 | 0GHz | 0MB | 予約なし |
アドミッションコントロールが有効に効いているか確認するために上記のような予約を割り当てました。メモリの予約だけで確認を行います。
起動確認
想定する動作
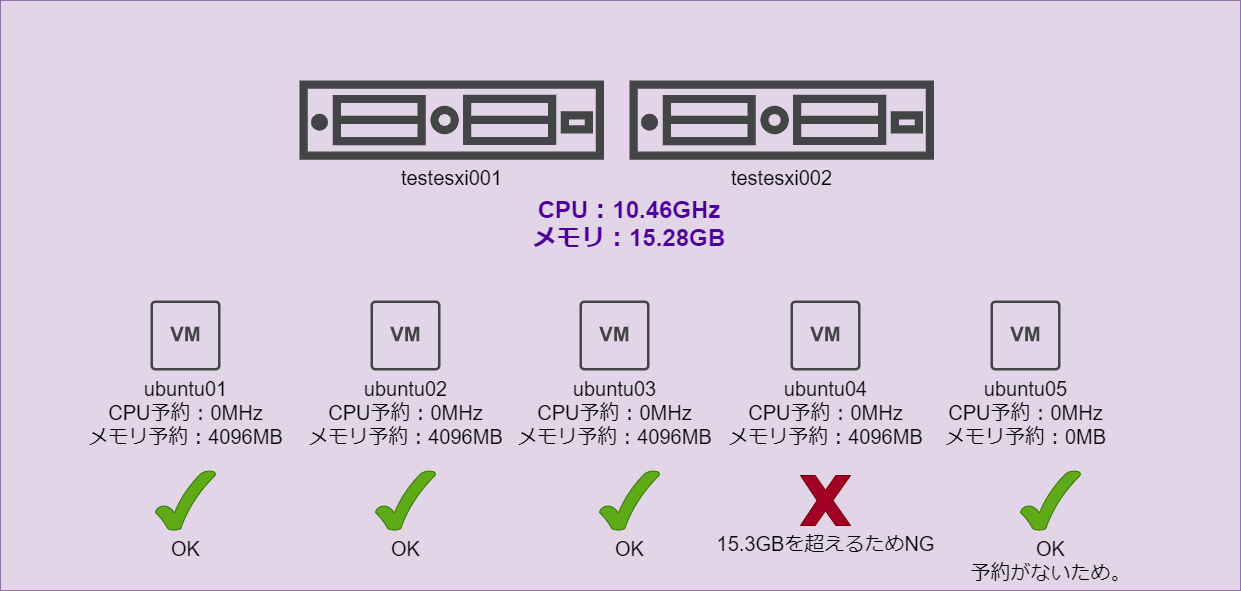
ubuntu01から順番に起動していくと仮想マシンとして利用できる15.3GBの仮想マシン(ubuntu04)を起動するときに制限がかかるはずでしたが、実際はUbunut03の起動時に制限がかかりました。
Ubuntu01起動(メモリ予約4GB)
Ubuntu01が正常に起動しました。メモリ予約の4GB分が使用済み予約に追加されました。少し多いのはメモリのオーバーヘッドが加算されています。
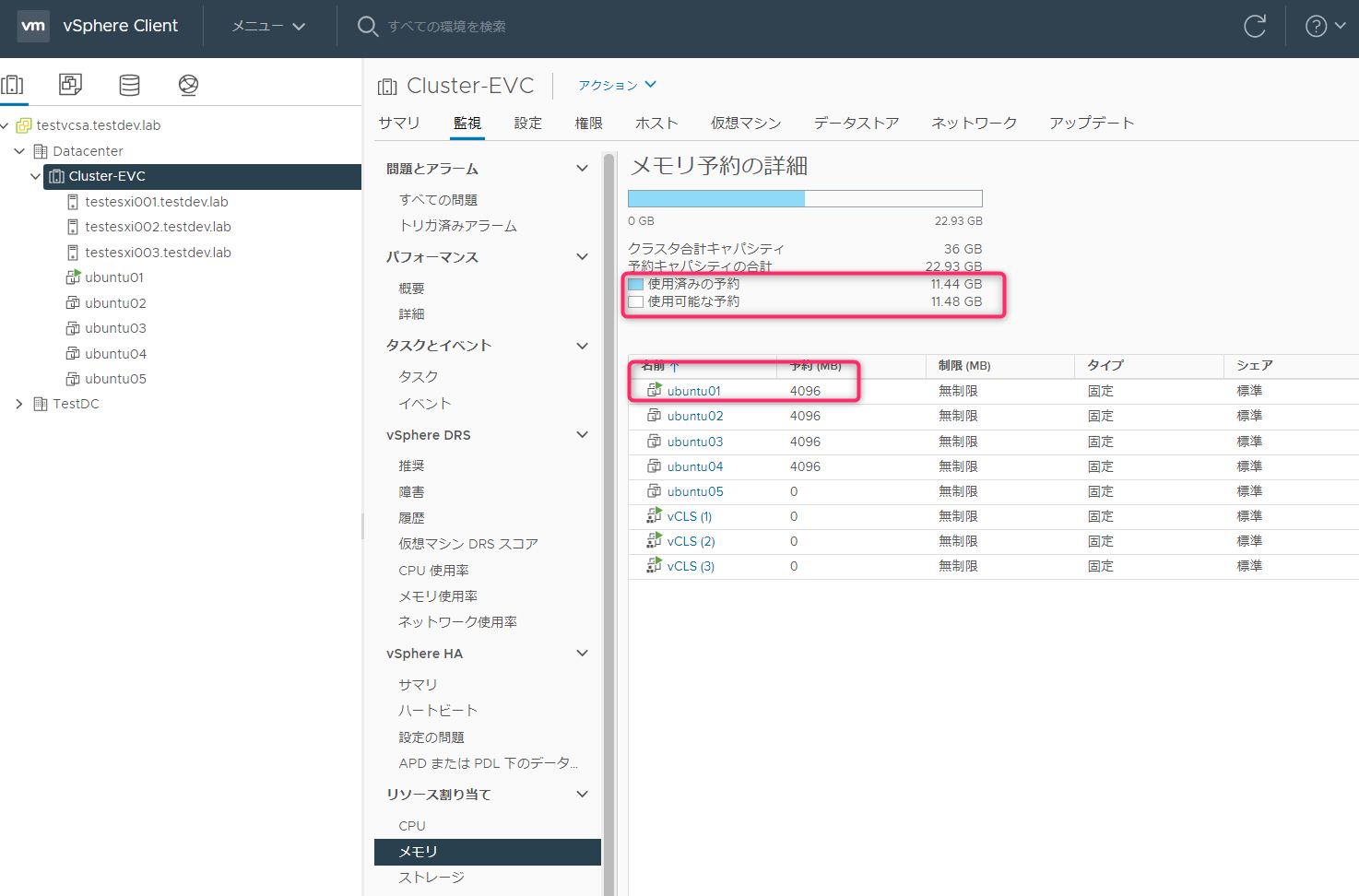
Ubuntu02起動(メモリ予約4GB)
Ubuntu02も正常に起動しました。メモリ予約の4GB分が使用済み予約に追加されました。

Ubuntu03起動(メモリ予約4GB)
Ubuntu03を起動しようとすると、「予約に十分なメモリリソースがホストにありません」が表示されます。
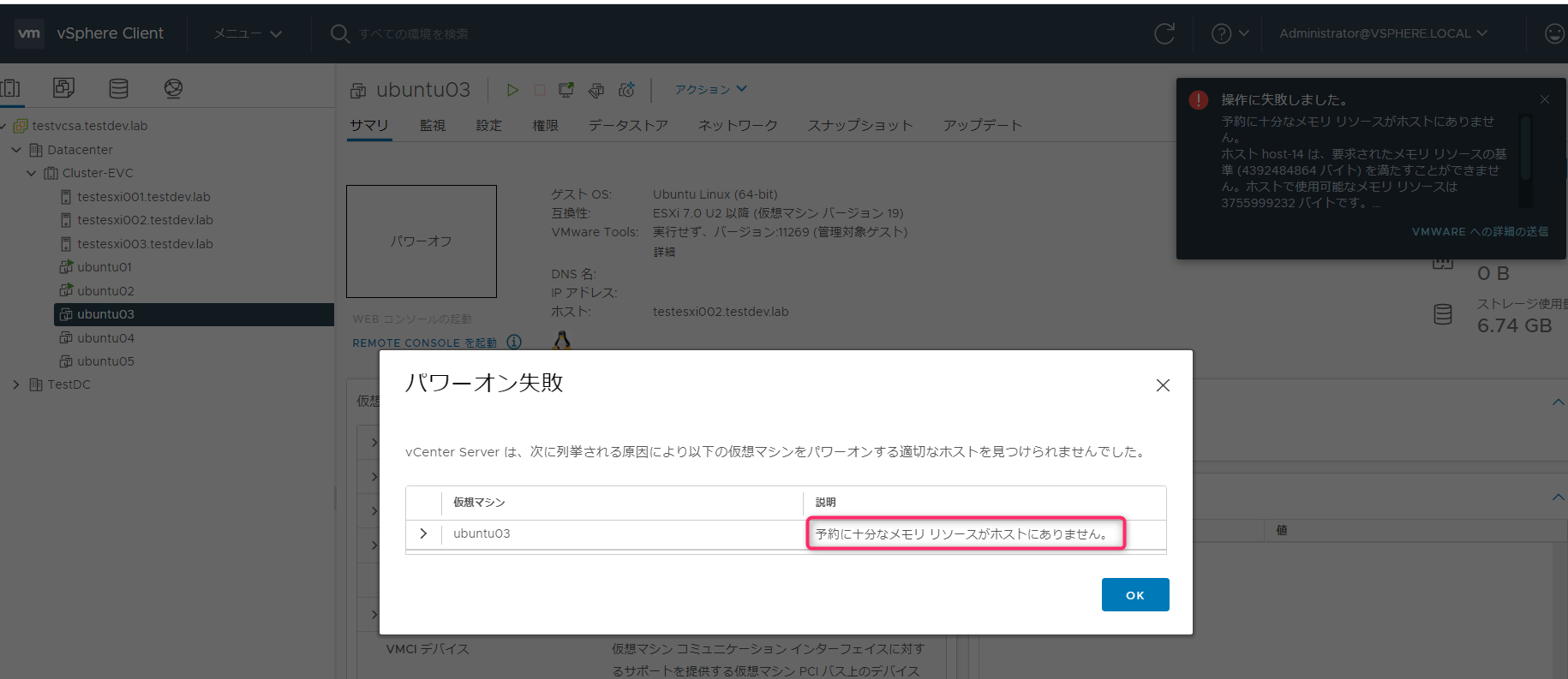
詳しくみると、ホストのメモリリソースが、約3.5GBしかないということです。

しかし、ルートリソースプールを見ると使用可能な予約が7.39GB存在する状態です。
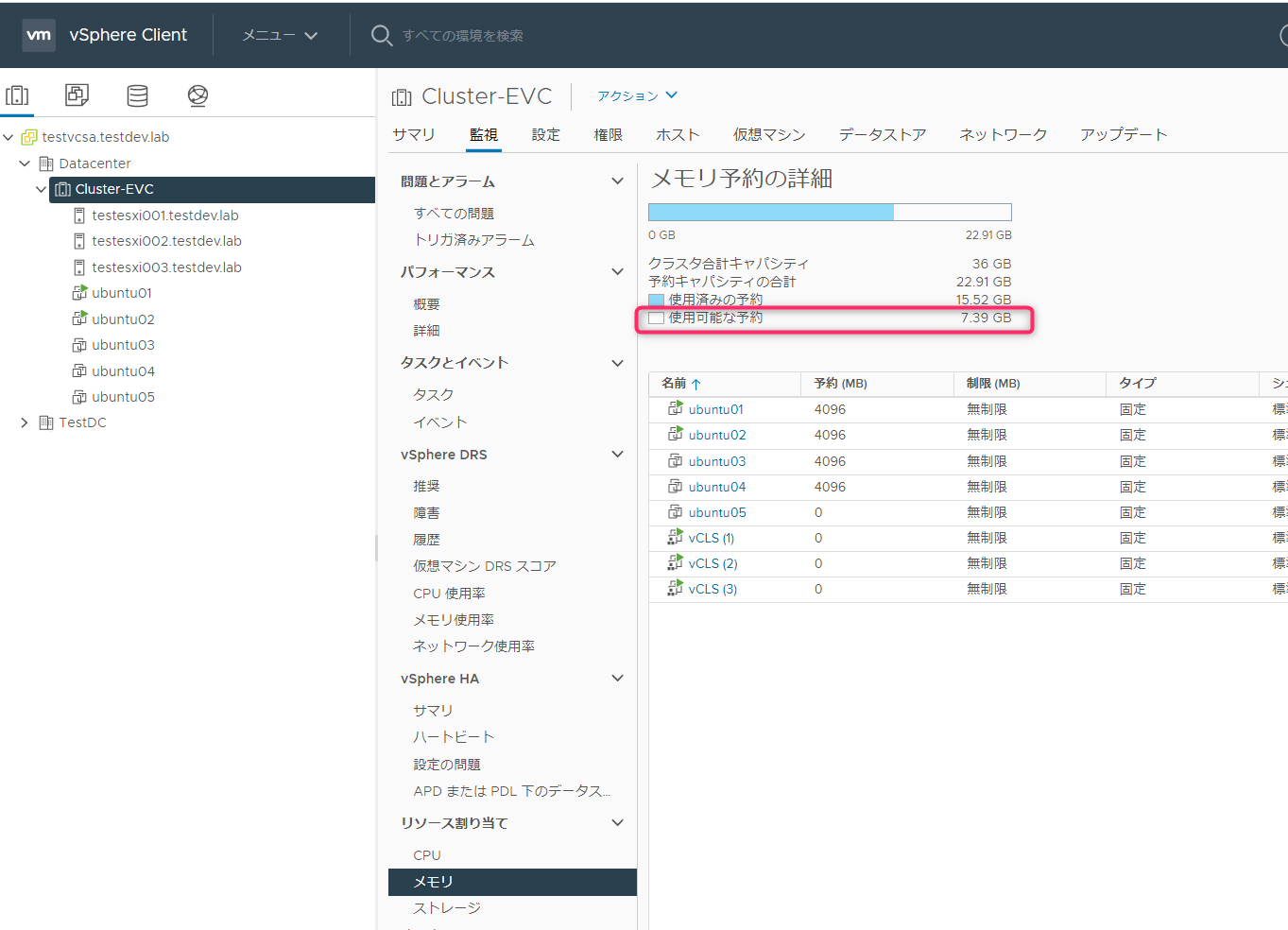
Ubunut03のメモリ予約を3GBまで減少させて起動したところ起動できました。使用可能な予約は4.3GBになります。
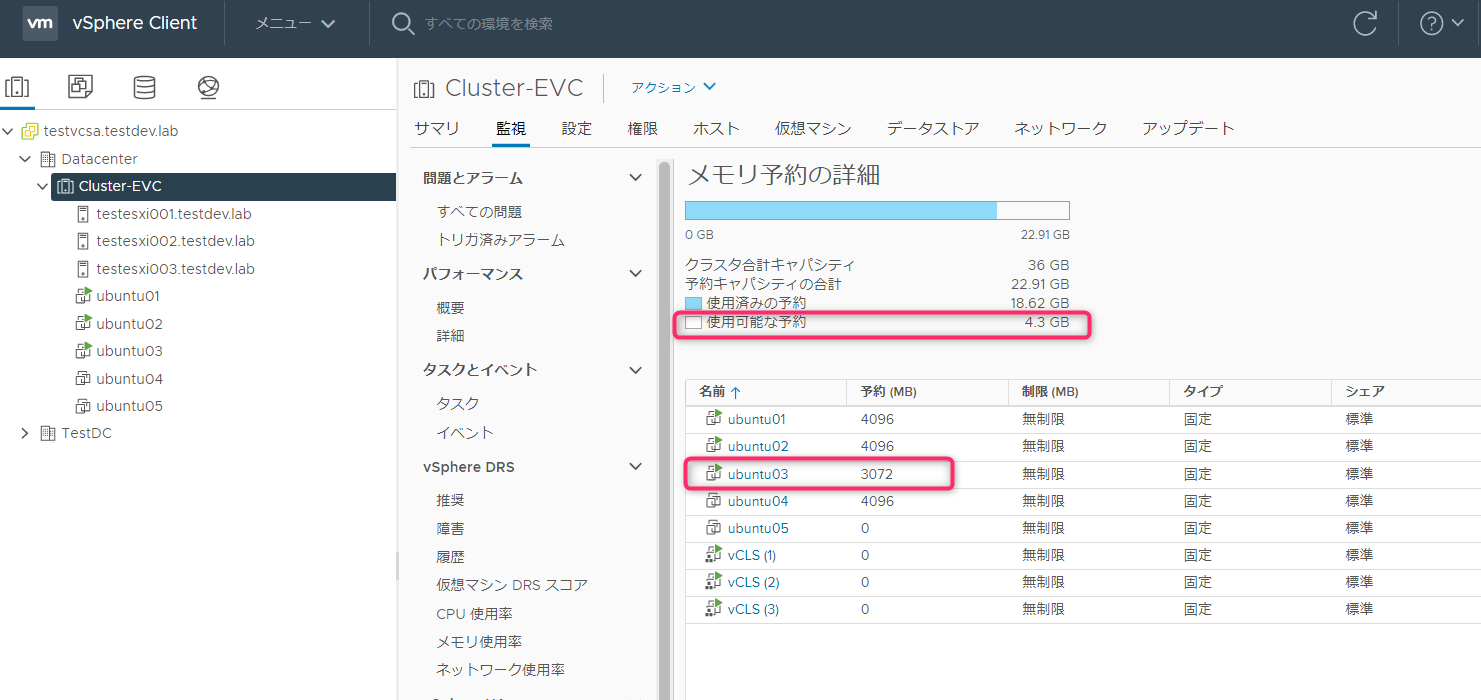
Ubuntu04起動(メモリ予約4GB)
続いてUbuntu04を起動しようとすると、「予約に十分なメモリリソースがホストにありません」が表示されます。
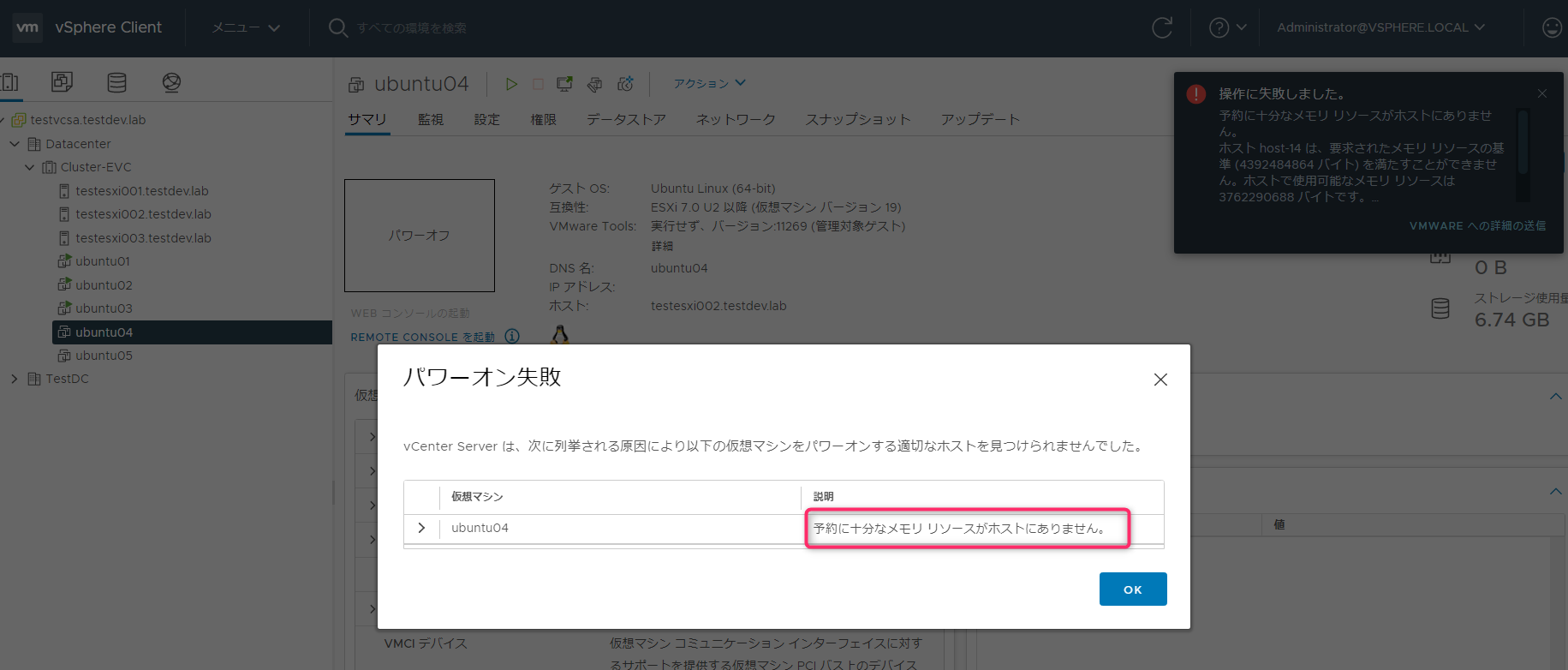
詳しくみると、またもや約3.5GBしかないということです。

Ubunut04のメモリ予約を3GBまで減少させて起動したところ起動できました。使用可能な予約は1.2GBになります。
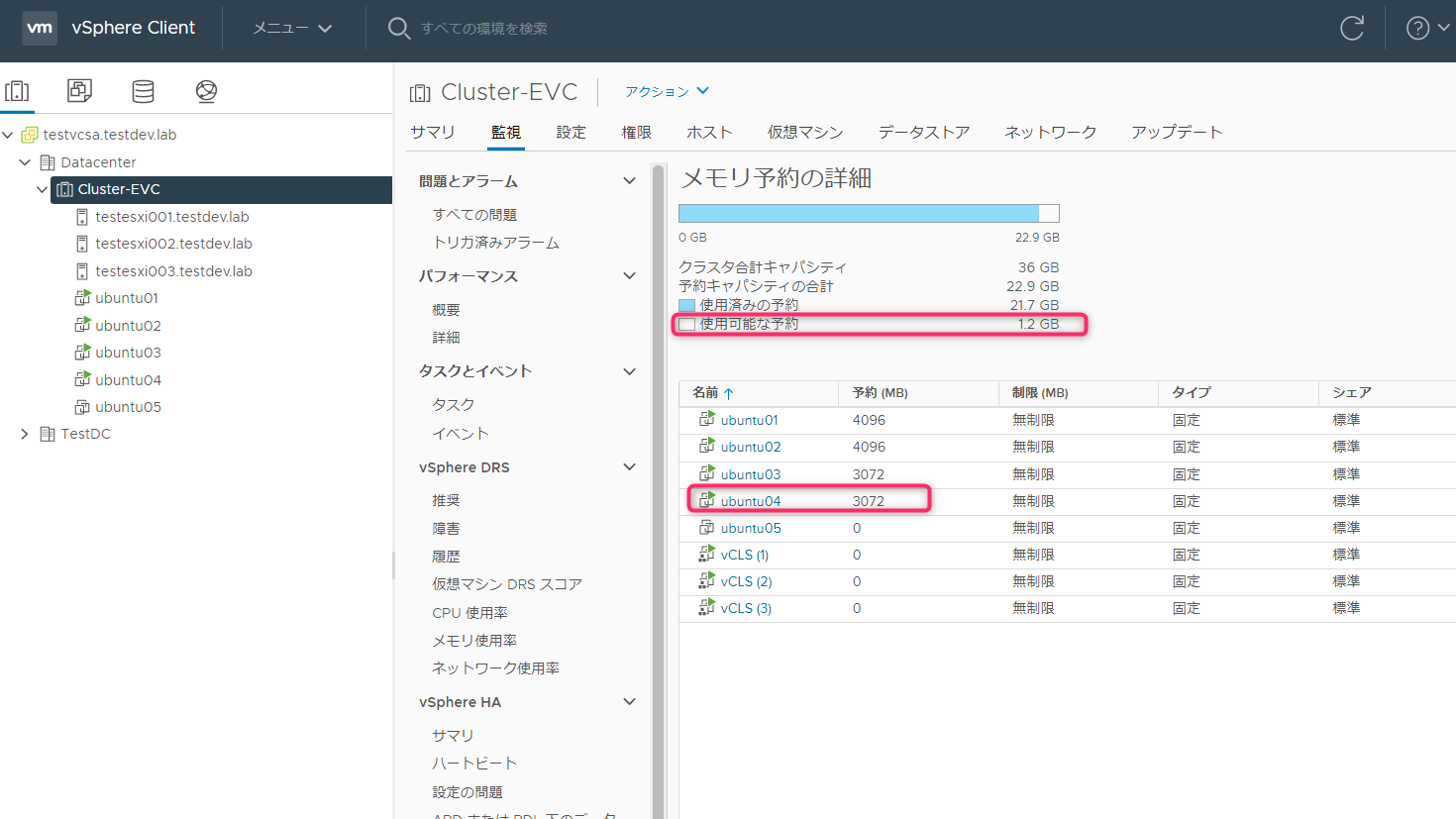
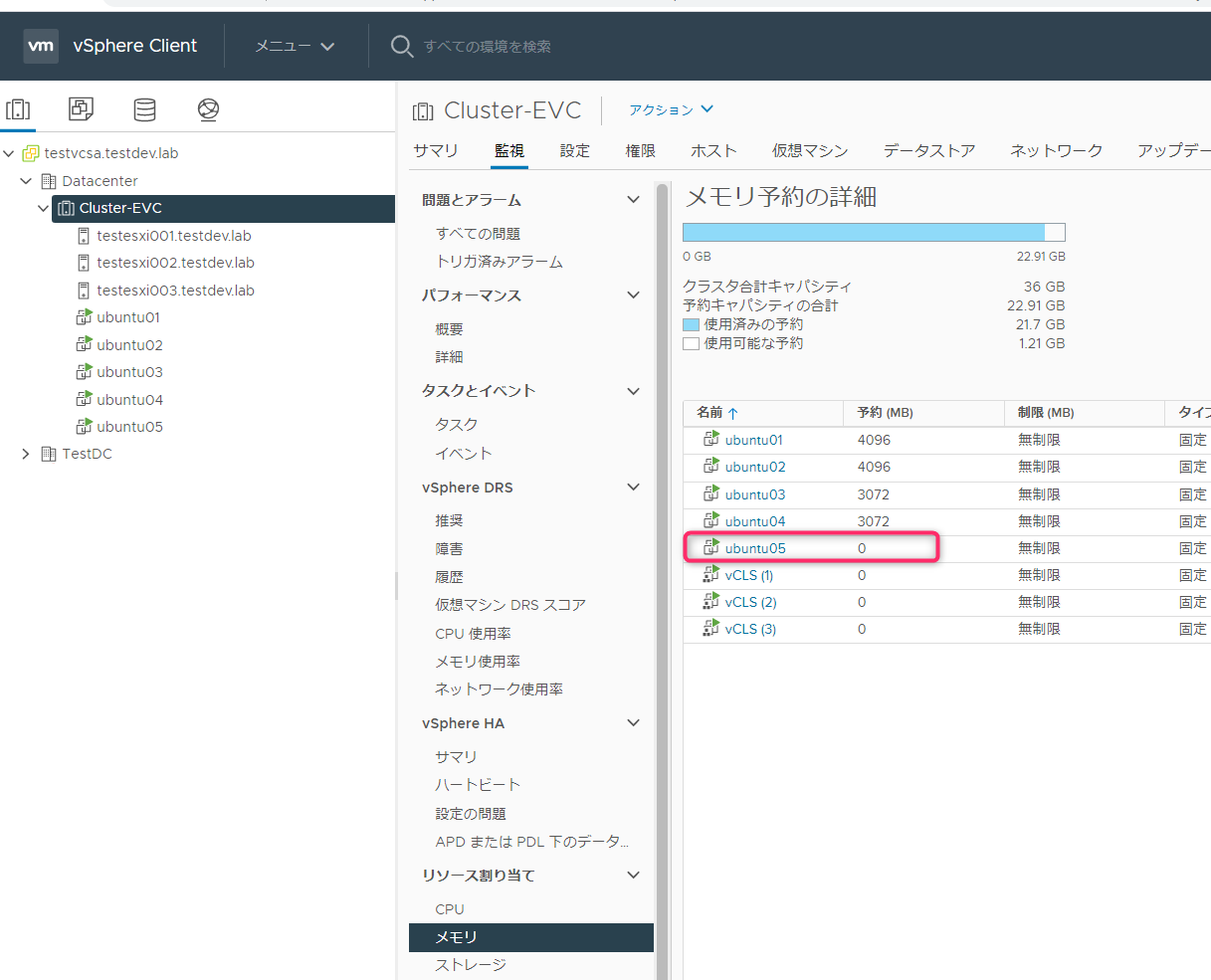
Ubuntu05起動(メモリ予約0MB)
Ubuntu05はメモリ予約をしていないため、起動が行えます。
おそらくホスト単位のメモリリソースの制約が原因と思われる
この事象は、おそらくホスト単位のメモリリソースの制約にかかっているのかと思われます。
ESXiホスト単体の物理メモリ:12GB
ホストには、予約4GBと3GBの計7GBの予約の仮想マシンが動かせました。

確認するすべはありませんが、ルートリソースプールに余力があったとしてもホスト単位でメモリが不足するような場合は、今回のようなエラーが出るのでしょう。
クラスタリソースの割合の検証では、ホストが3台あったため、予約4GB×3台の仮想マシンを動かせましたが、今回2台になったことで露呈しました。
フェイルオーバーホストでvCLSは起動できるっぽい?
専用フェイルオーバーホストの場合、下記の引用のように仮想マシンをパワーオンできない記載があります。
フェイルオーバー ホストで予備のキャパシティを確実に使用できるようにするため、仮想マシンをパワーオンすること、または vMotion を使用して仮想マシンをフェイルオーバー ホストに移行することはできません。
しかしvCLSを見るとフェイルオーバーホストでも稼働していました。これが正しい仕様なのかはわかりませんが、現状vCLSはフェイルオーバーホストでも稼働できるようです。
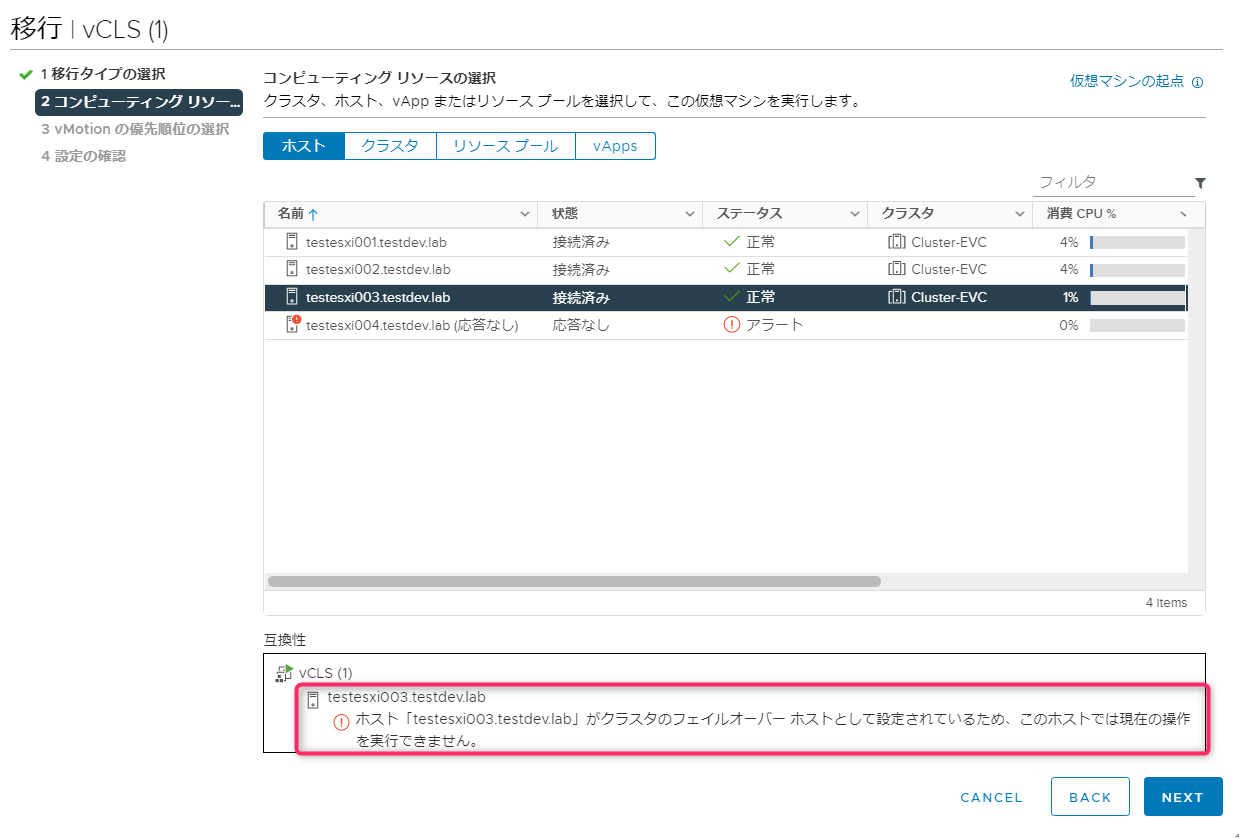
しかし他のホストにあるvCLSをvMotionはできないようです。システム任せですね。
許容するパフォーマンスの低下
クラスタリソースの検証で、予約値がルートリソースプールを超えなくとも、実使用量が超えると制限はかからないが「実行中の仮想マシンの使用率では、設定されている<クラスタ名>のフェイルオーバーリソースを満たすことができません」が表示されることを確認しました。
この事象は、「クラスタリソースの割合」「スロットポリシー」「専用フェイルオーバーホスト」いずれでも発生する可能性があります。
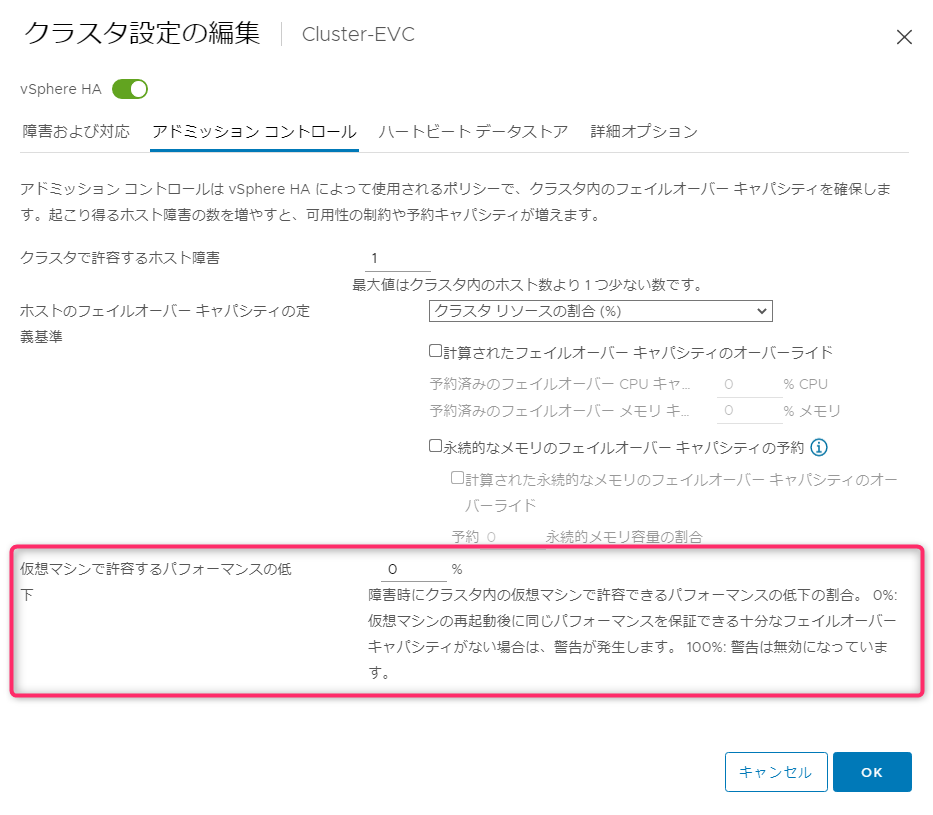
アドミッションコントロールの設定で、「クラスタリソースの割合」「スロットポリシー」「専用フェイルオーバーホスト」のすべてで「仮想マシンで許容するパフォーマンスの低下」設定があります。デフォルト0%のため、現状消費しているリソースに対してキャパシティが足りない場合に先ほどの警告が表示されます。ここを100%にすることで警告を抑止もしくは、50%など低下までは抑止するなど変更することができます。
参考


まとめ
オプション項目もどんどん増えるのでおいかけるのが大変(´・ω・`)