どうも、Tです。
僕は本が大好きですが、多すぎて紙のまま保存できないので、自炊をしてPDFファイルで保存しています。


そんな自炊したPDFファイルで困ったことを放置してましたが、抜本的に見直したお話です。
目次
自炊でPDFファイル保存して困ったこと
自炊する際に、将来的にも困らないように最高画質で取り込みを行って読んでますが、色々と問題にぶち当たりました。
PDFファイルサイズが大きすぎる問題
最高解像度で自炊しているので、3000冊強で1.3TBほど消費しています。ファイル単体だと1冊あたり「300MB~1GB」になります。
ファイルサイズが大きいことで下記の問題が発生しました。
- PDFファイルを開く、次のページに進むといった動作がすごい遅い
- ファイルサイズが大きいため、ノートPCに全部入れて持ち歩くことができない
- ファイルサイズが大きいため、他にコピーしたりが億劫
PDFファイル圧縮がすごい大変問題
圧縮前PDFファイルは保存用として、圧縮後PDFファイルはその時に応じた解像度まで圧縮し普段使いとして利用しようと考えましたがここでも下記のような問題が発生しました
- PDFファイル圧縮する方法やツールはあるが、1つ1つ手動で行うものが多い
- 圧縮前のファイル名を保持して一括圧縮するツールが見つからない
- 圧縮前のフォルダ構造を保持して一括圧縮する方法がない(圧縮後のファイルを手動で仕訳しないといけない)
やりたいこと
ということで、コマンド一発で後は自動的に行ってくれるスクリプトを自分で作ってしまうことにしました。
具体的にやりたいことは、下記になります。
- PDFファイルを自動で圧縮したい
- 元のPDFファイルは残したい
- フォルダ構造・ファイル名は圧縮後も同じにしたい
- 上のことを全部自動化したい(1ファイルずつ手動でやるのは嫌)
ちなみに、以下のようなフォルダ管理をしており、適当となるフォルダにPDFファイルを保存するような形で管理しています。
![]()
方法
gs(Ghostscript)を使う
PDFファイルを圧縮する方法を調べたところ、スクリプトで行う方法としてgsを使うことにしました。圧倒的に情報量が多かったため。

gsのコマンド例
gsコマンド自体は、非常に簡単で以下のような感じでPDFファイルを圧縮することができます。
###gs(Ghostscript)オプション説明### # -dNOPAUSE:入力ファイルを1つ処理完了したら、次の入力ファイルを処理する # -dBATCH:変換処理が完了したらgsを終了する # -sDEVICE=pdfwrite:ファイルの出力方式を指定。PDFファイルに変換を指定している。 # -dCompatibilityLevel=1.4:PDFバージョンを指定。ここでは1.4を指定している。 # -dPDFSETTINGS=/ebook:出力用途(品質)を指定。ここではebook(電子図書)を指定している。 # -sOutputFile:変換後の出力先パス、ファイル名を指定。 ### gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -sOutputFile=output.pdf input.pdf
品質の-dPDFSETTINGSオプションについては、下記に詳しく記載されています。


自動化の概要フロー
スクリプトファイルは、「ebook_compress.sh」です。圧縮前のPDFファイルの保存場所は「/foo」フォルダ配下、圧縮後のPDFファイルの保存場所は、「bar」フォルダ配下を想定です。
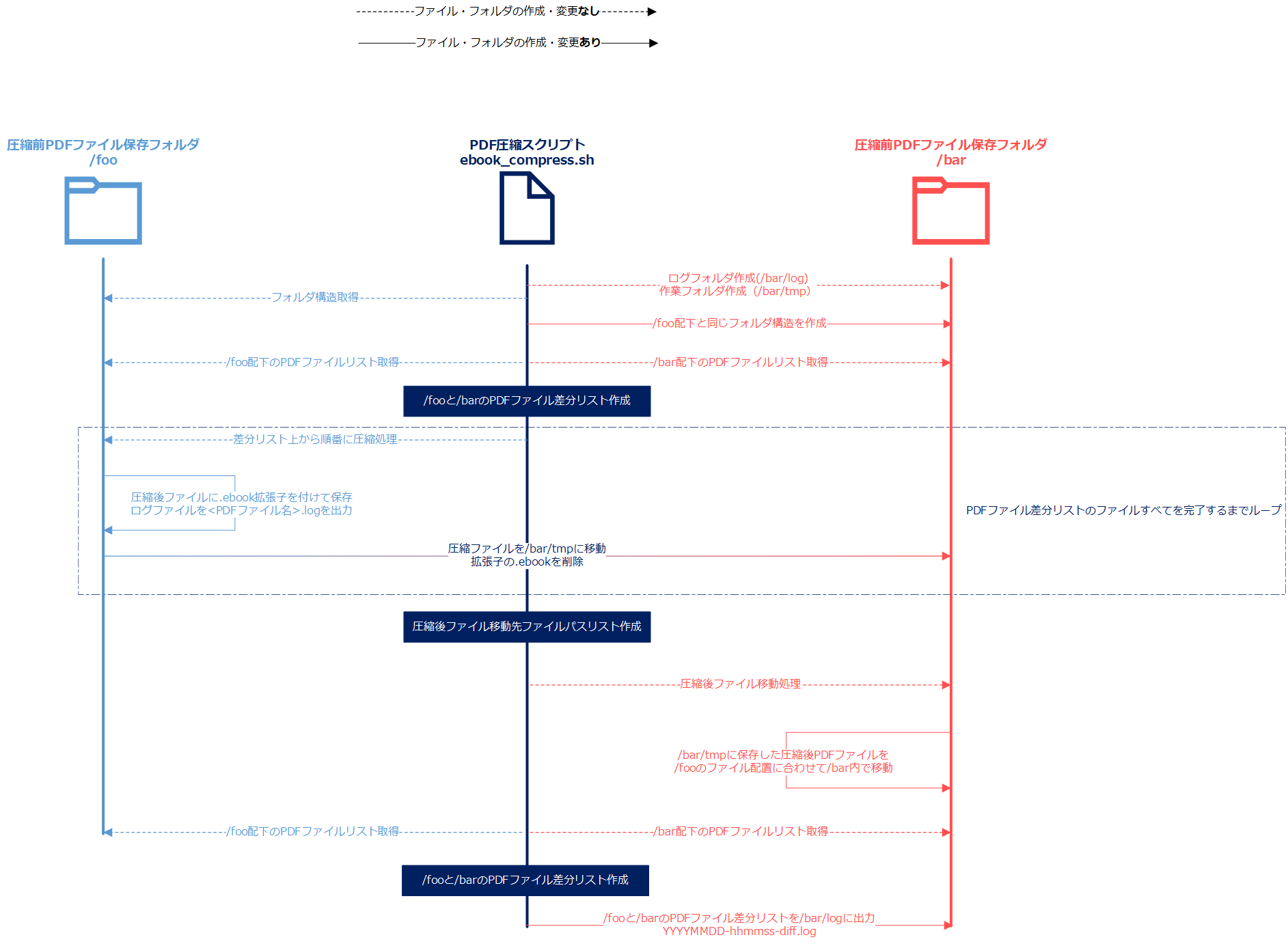
自動化スクリプト(ebook_compress.sh)
というわけで、自動化スクリプト(ebook_compress.sh)を作成しました。
説明面倒なので、細かい処理はスクリプト読んでください・・・。
注意事項
- ebook_compress.shを動かす際は、自己責任でお願いします。
- 圧縮前PDFファイルに影響無いように作成しているつもりですが、事前にバックアップを取得するかテスト環境で実施してください。
- CPU使用率が常時80%以上になります。物理コア6コア以上で動かすか、スクリプト内のxargsの-P6(6プロセス)の上限値を小さい値、例えば-P1(1プロセス)などに変更してください。
- ebook_compress.shにより損害が発生しても、いかなる責任も負いません。
- 圧縮対象は、PDFファイルのみです。jpgやpngは圧縮できませんし、そもそも処理対象とされないためスキップされます。
動作環境
PowerShellでもよかったのですが、色々な環境で使えるようにするためbashで作成しました。WSL上のUbuntuで動作確認しています。
- OS:Windows10 バージョン1903
- WSL:WSL1
- Ubuntu:Ubuntu 16.04.2 LTS
WSLでなくても普通のUbuntuでも動作すると思います。
CentOSではrenameコマンドの書式が異なるため、動きません。renameコマンドの処理部分をCentOS用に書き換えれば動きます。
動作環境準備
ebook_compress.shを動かす方は、「ghostscript」「rename」パッケージをインストールしてから動かしてください。
ghostscriptパッケージ
必要な理由:PDFの圧縮処理に必要
導入方法:
sudo apt update
sudo apt install ghostscript
renameパッケージ
必要な理由:ファイルのリネーム処理に利用
導入方法:
sudo apt-get install rename
ebook_compress.sh実行方法
WSL上で下記のコマンドを実施してください。-xオプションは付けなくても動きますが、つけると実行状況を把握しやすいです。
sudo bash -x /<PHAT>/ebook_compress
ebook_compress.shファイルダウンロード
ファイルは、下記からダウンロードください。
■ダウンロード一覧
ebook_compress_v1.0.1:圧縮後も検索可能に修正
ソースコードは、下記のようになっています。
#!/bin/bash
################################################################################
#@(#)ebook_compress ver1.0.0 2020.07.07
#
# 概要:
# PDFファイルを解像度を落としPDFファイルサイズを縮小します。
# 変換前と変換後のディレクトリを比較し、未変換のファイルのみ変換処理します。
# 存在しないディレクトリは、変換前のディレクトリ構造を維持します。
#
# 使い方:
# 本スクリプトを実行すれば、指定した変換前ディレクトリと変換後ディレクトリを比較し、処理が始まります。
#
# 動作環境:
# OS:Windows10
# ツール:WSL
# ディストリビューション:Ubuntu 16.04.2 LTS
# 注意事項:WSL以外のUbuntuでも動作可能。CentOSではrenameコマンドの書式が異なる。
#
#
# 事前準備:下記のパッケージを導入する。
# パッケージ:ghostscript
# 必要な理由:PDFの圧縮処理に必要
# 導入方法:
# sudo apt update
# sudo apt install ghostscript
#
#
# パッケージ:rename
# 必要な理由:ファイルのリネーム処理に利用
# 導入方法:
# sudo apt-get install rename
#
# 必須作業:
# 下記の定数定義の値は、環境により変更必須。
# BEFORE_DIR:圧縮対象のPDFが存在するフォルダ
# AFTER_DIR:圧縮後のPDFを出力するフォルダ
# ※AFTER_DIRのフォルダ構造・ファイル名は、BEFORE_DIRの内容を維持します。
#
# 変更履歴:
# 2020/07/07 1.0.0 新規作成。
#
################################################################################
################################################################################
## 変数・定数定義
################################################################################
##変数定義
#trap定義 mktempで作成した一時ファイルをスクリプト終了時に自動削除
trap "rm -f /tmp/tmp.*; exit 1" 0 1 3 15
#スクリプトで利用する一時ファイルを作成。/tmp/tmp.<ランダム名>.--suffix名のファイルを作成
tmp_dest_file_name=`mktemp --suffix=-dest` #compress元ファイル一覧
tmp_src_file_name=`mktemp --suffix=-src` #compress先ファイル一覧
tmp_diff_file_name=`mktemp --suffix=-diff` #未compressファイル名一覧
tmp_convert_list_tmp=`mktemp --suffix=-list_tmp` #未compressファイル名フルパス(未sort)
tmp_convert_list=`mktemp --suffix=-list` #未compressファイル名フルパス(sort済)
tmp_src_move_list=`mktemp --suffix=-src_move` #compress済みファイル移動元リスト
tmp_dest_move_list=`mktemp --suffix=-dest_move` #compress済みファイル移動先リスト
##定数定義
#compress元ディレクトリ
readonly BEFORE_DIR='/foo' #ここのパスは書き換えてください
#compress先ディレクトリ
readonly AFTER_DIR='/bar' #ここのパスは書き換えてください
#compress作業ディレクトリ
readonly TMP_DIR="$AFTER_DIR/tmp"
#compressログ
readonly LOG_DIR="$AFTER_DIR/log"
#区切り文字を改行コードへ変換###################################################
#スペースなどを区切り文字と認識しないように対策
IFS=$'\n'
################################################################################
## ディレクトリ作成
################################################################################
#ログディレクトリ作成###########################################################
[ ! -e $LOG_DIR ] && mkdir -p $LOG_DIR
#作業ディレクトリ作成###########################################################
[ ! -e $TMP_DIR ] && mkdir -p $TMP_DIR
#compress先ディレクトリ作成#####################################################
#ディレクトリ構造取得、置換
#sedはファイルパスを扱うため、/ではなく#で指定
array_convert_dir=`find $BEFORE_DIR -type d | sed -e s#$BEFORE_DIR#$AFTER_DIR#g`
#compress先ディレクトリ作成
for dir in $array_convert_dir;
do
mkdir -p $dir
done
################################################################################
## ファイルリスト作成
################################################################################
##compress対象ファイルリスト作成################################################
#compress元ファイル一覧取得
find $BEFORE_DIR -type f -name *.pdf | gawk -F/ '{print $NF}' | sort --version-sort > $tmp_src_file_name
#compress先ファイル一覧取得
find $AFTER_DIR -type f -name *.pdf | gawk -F/ '{print $NF}' | sort --version-sort > $tmp_dest_file_name
#未compressファイル名一覧作成
###diffオプション説明###
# --side-by-side:2列出力
# --suppress-common-lines:side-by-side形式で共通な行を表示しない
###
diff --side-by-side --suppress-common-lines $tmp_src_file_name $tmp_dest_file_name | gawk '{print $1}' > $tmp_diff_file_name
#未compressファイル フルパスリスト作成#########################################
cat $tmp_diff_file_name | while read line
do
find $BEFORE_DIR -type f -name *${line}* >> $tmp_convert_list_tmp
done
#ファイル名ソート
###sortオプション説明###
# --version-sort:自然な(バージョン)数字順で並べ替える
###
cat $tmp_convert_list_tmp | sort --version-sort > $tmp_convert_list
################################################################################
## compress処理
################################################################################
##pdf圧縮処理→圧縮後ファイルを一時フォルダに移動→ログファイルをログフォルダへ移動
###xargオプション説明###
# -t:実行前にコマンドラインを標準エラー出力へ出力する
# --no-run-if-empty:標準入力が空の場合は指定したコマンドを実行しない
# -L1:1コマンドラインで1行を利用する指定
# -P6:同時に実行するプロセス数の上限を指定する
# -I:xargs実行時に指定したコマンドの引数のうち、置換文字部分を標準入力から読み込んだ名前で置き換える
# 注意:ファイル名に空白、記号が入っても処理できるように{}は'{}'とする
###
###gs(Ghostscript)オプション説明###
# -dNOPAUSE:入力ファイルを1つ処理完了したら、次の入力ファイルを処理する
# -dBATCH:変換処理が完了したらgsを終了する
# -sDEVICE=pdfwrite:ファイルの出力方式を指定。PDFファイルに変換を指定している。
# -dCompatibilityLevel=1.4:PDFバージョンを指定。ここでは1.4を指定している。
# -dPDFSETTINGS=/ebook:出力用途(品質)を指定。ここではebook(電子図書)を指定している。
# -sOutputFile:変換後の出力先パス、ファイル名を指定。
###
cat $tmp_convert_list | \
xargs -t --no-run-if-empty -L1 -P6 -I{} bash -c \
"\
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -sOutputFile='{}'.ebook '{}' &>> '{}'.log;\
mv '{}'.ebook $TMP_DIR;\
mv '{}'.log $LOG_DIR
"
################################################################################
## 圧縮後ファイル最終処理
################################################################################
#ファイルリネーム###############################################################
#一時フォルダに移動したファイルを変更
rename "s/.pdf.ebook/.pdf/" $TMP_DIR/*
#ファイル移動処理###############################################################
#移動元ファイルリスト作成
###lsオプション説明###
# -1:ファイル名を1列で表示。
###
ls -1 $TMP_DIR > $tmp_src_move_list
#移動先ファイルパスリスト作成
cat $tmp_convert_list | sed -e s#$BEFORE_DIR#$AFTER_DIR#g > $tmp_dest_move_list
#圧縮後ファイルを一時フォルダから本来あるべきフォルダへファイル移動
cat $tmp_src_move_list | while read line
do
cat $tmp_dest_move_list | grep $line | sed -z 's/$line//' | xargs -I{} mv $TMP_DIR/$line {}
done
################################################################################
## 圧縮後差分ファイルリスト作成
################################################################################
##compress対象ファイルリスト作成################################################
#compress元ファイル一覧取得
find $BEFORE_DIR -type f -name *.pdf | gawk -F/ '{print $NF}' | sort --version-sort > $tmp_src_file_name
#compress先ファイル一覧取得
find $AFTER_DIR -type f -name *.pdf | gawk -F/ '{print $NF}' | sort --version-sort > $tmp_dest_file_name
#差分ファイルリスト作成
###diffオプション説明###
# --side-by-side:2列出力
# --suppress-common-lines:side-by-side形式で共通な行を表示しない
###
diff --side-by-side --suppress-common-lines $tmp_src_file_name $tmp_dest_file_name | gawk '{print $1}' > $LOG_DIR/`date +"%Y%m%d-%H%M%S"`.diff
exit 0
どうなったか
PDFファイルサイズが大きすぎる問題の解決
結果のご報告です。
圧縮前後のファイルサイズを並べてみました。
文字の多い技術書は、おおむね1/10程度まで小さくなりました。コミックなどは、1/20程度まで小さくなっているので絵やイラストが多いほど小さくでできそうです。
![]()
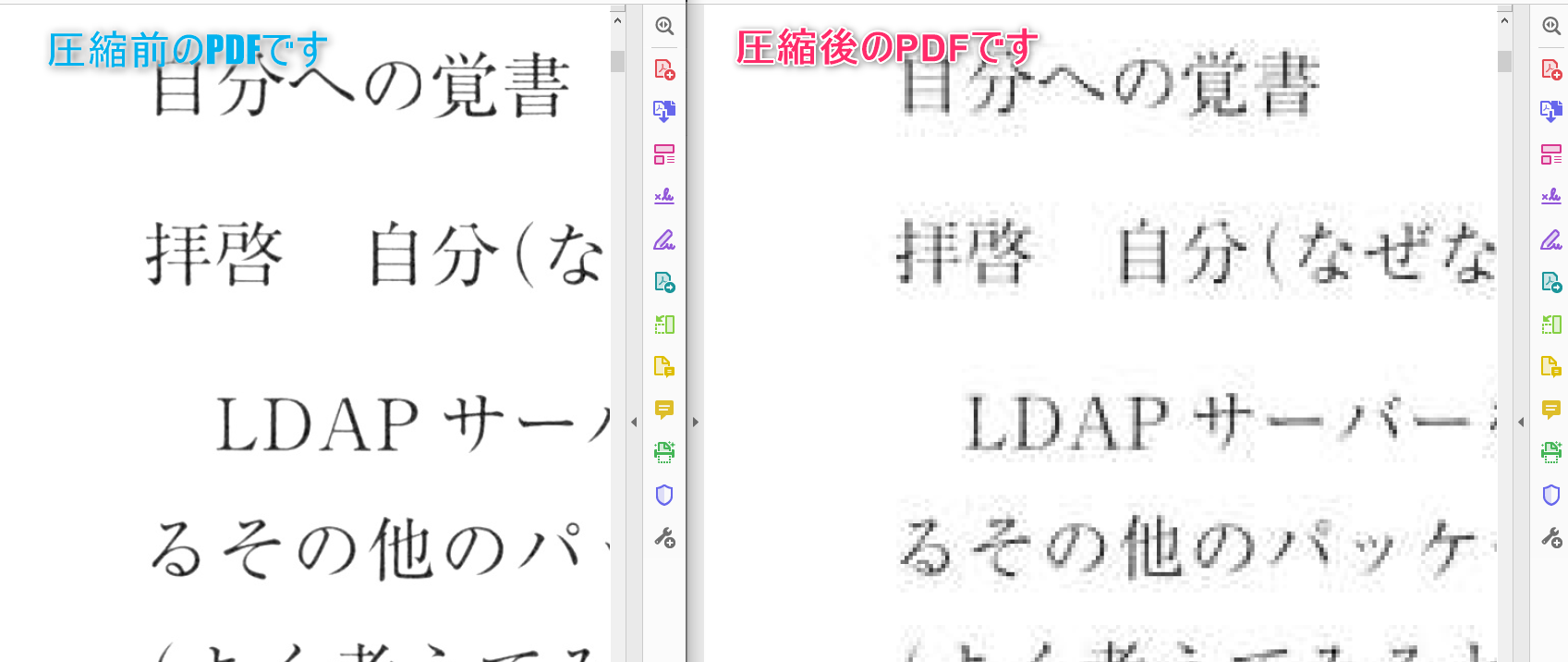
画質の比較です。粗さが見られますが読む分には問題ないレベルです。コミックなども目視で滲みがわかるレベルでしたが読む分には問題ありませんでした。
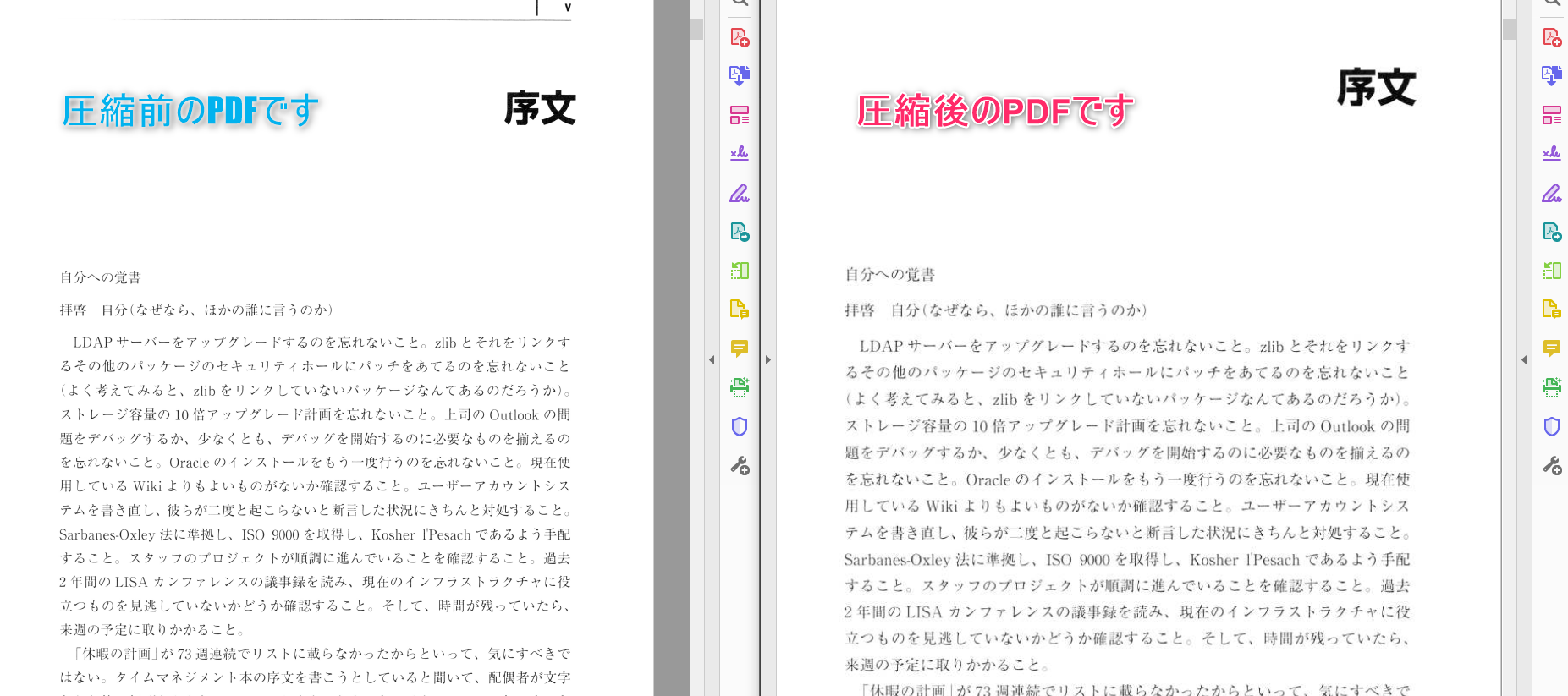
拡大するとさすがに粗さが目立ちます。イラスト集や画集などはちょっと厳しそうです。
PDFファイル圧縮がすごい大変問題の解決
コマンド一発実行して、放置でできるのでかなり簡単になりました。
フォルダ構造も同じになり、圧縮後のPDFファイルも自動で配置してくれるのは非常に楽です。

圧縮の処理時間ですが、大部分がCPUに依存します。
時間とるスクリプト仕込むのが面倒だったので目視確認ですが、CPUにAMD Ryzen 7 1700を使ってコミック1冊あたり1分前後でした。今回のebook_compress.shでは6並行で圧縮処理を行うようにしていますが、他の操作をしないのであれば16並行(全コア)利用でも大丈夫そうです。
ebook_comrepss.shについて
良いところ
コマンド一発放置
やはりコマンド一発でできるというのが一番いいところでしょう。必要な時に手動で実行するもよし!PDFをLinuxNASに保存しているのであれば、NASのcronに仕掛けるもよし!です。自炊した後の、面倒な圧縮処理を手でする必要がなくなりました。
特にフォルダの仕訳は難儀していたので、非常に楽になりました。
ファイルサイズをかなり抑えられる
圧縮前のPDFファイル総容量1.3TBが、圧縮後のPDFファイル総容量50GBまで小さくなりました。タブレットのSDカードにすべて入れて持ち運んでいます。
当たり前ですが、ページめくりも非常にスムーズです。
悪いところ
検索可能なPDFではなくなる
スクリプトを作り終わったとに気づきました・・・・。
専門書などは自炊スキャン時にORCして、検索可能なPDFにしている方も多いかと多いかと思いますが、ebook_compress.shを行った圧縮後のPDFでは、検索できなくなっていました・・・・。検索機能を普段使っていないので失念してました。
gsのオプション詳しく調べてみるか、下記のような方法でゆくゆく修正できればなぁと考えています。


2020.07.09追記
こちらの問題は、「-dCompressFonts=false」を付けることで解決しました。
ebook_compress_v1.0.1.shが修正版になります。
詳細は、記事にしております。


実行環境依存が強い
Windows10+WSL+Ubuntuという一般からするとかなり面倒な環境で変換するようにしています。
これも色々考えたのですが、
「自炊はWindows10でローカルHDDに保存している+Power Shellは使いたくない」と考えたときに、仮想マシンを使うかWSLを使うかに迫られて、外部の仮想マシンからWindows10のCIFSを見て変換するというものを作ったのですが、CPUがボトルネックになり数倍以上に時間がかかったので諦めました。
なんやかんやWSLからCPUリソースを使うというのは、かなり早いと実感できました。
1回目は最後まで処理する必要がある
スクリプト作るのに疲れ果ててあきらめた部分です。
動きとして、下記のように面倒なことをしています。
- /fooフォルダ配下のインプットファイルと同じフォルダにアウトプット(圧縮ファイル)
- 圧縮したしたファイルを/bar/tmpに集める
- /bar配下の正しいフォルダに再配置する
2回目以降では、差分ファイル(圧縮されていないPDFファイル)のみ、圧縮処理がかかりますが、最初の1回はすべてのファイルが圧縮処理の対象となるため上の1~3を終わらせる必要があります。
1~3の途中でスクリプトを止めてしまうと、また1から再度やり直さないといけないので、最初の1回はすごく時間がかかります。
/barの配下に直接アウトプットしたかったのですが、xargsを使って並列処理をしながら実装するのが面倒そうだったので、諦めました。わかる人いたら教えてください。
フォルダ・ファイル名変更したファイルは削除されない
圧縮後に、圧縮元・先のどちらかのフォルダ名やファイル名を変更すると再度圧縮処理がかかります。特に圧縮前のファイル名を変更しても、圧縮先では新しいファイル(名前変更後のファイル)が作成されて、先に圧縮していたファイルは自動削除されません。
比較方法を簡素化するためこのようになってます。作れるけどめんどくさい・・・ファイル名変えないし・・・・。
進捗率がわからない
夜に実行して放置してるので進捗率付けるのやめました・・・作るのめんどくさいし・・・・。
ログがでない
エラーログとかも特に出してないです・・・・画面でみりゃいいかな状態。作るのめんどく
同じファイル名があると・・・?
これも比較方法の問題です。異なったフォルダに全く同じファイル名があると、圧縮の際にいずれかの圧縮後のファイルが上書きされます。
※どれが上書きされるかは保存されているパスによってsort順番かわるのでわかりません。
対応できない文字列・・・?
どのようなファイル名を付けても圧縮処理されるようにしているつもりなんですが、エラーがでるかもしれません・・・めんどくさくて最低限しかテストしてません。
下記の文字は、OKであることを確認しています。
「半角スペース・全角スペース」
「’ (半角シングルクォーテーション)」
「- (半角ハイフン・全角ハイフン)」
「~ (半角チルダ・全角チルダ)」
「!(半角エクスクラメーションマーク・全角エクスクラメーションマーク)」
「_(半角アンダーバー・全角アンダーバー)」
「&(半角アンパサンド・全角アンパサンド)」
「@(半角アット・全角アット)」
「★とか(ほしなどの記号)」
2020年7月27日追記
ファイル名に[]が入っていると圧縮後のファイル移動処理が失敗することがわかりました。改修は面倒なので、ファイル名に[]を付けないようにしています。
参考サイト




まとめ
とりあえず自分の用途としては満足。